
AI-Generated Code Is Just Untrusted Code From the Internet
Harshil Agrawal (X, LinkedIn), a Senior Developer Educator at Cloudflare, opened his AI Engineer Europe talk with a reframe that should be obvious but apparently isn't: strip away the branding, and the code your LLM writes deserves exactly as much trust as code you found on a random website. Which is to say, none.
"If you told someone, hey, I found this code snippet on a random website on the internet, let's run it in production, you would absolutely not do that. That's security 101. But that's essentially what we are doing with LLM generated code. We just dress it up nicer."
The model has no intentions and no loyalty, Agrawal argues. It's a function that produces text that looks like code. The same LLM that writes working React components can be tricked into exfiltrating your database -- not because it's malicious, but because it's a text predictor that doesn't understand security boundaries. And yet teams routinely execute its output with full production privileges: file system access, environment variables, database credentials, API keys.
We Already Know How to Solve This
Harshil's central point is that this isn't a new problem requiring a new paradigm. Browsers sandbox JavaScript. Mobile operating systems sandbox apps. The principle of running untrusted code in constrained environments is decades old. What's happened with LLM-generated code, he argues, is that the excitement of shipping AI features has caused teams to forget these fundamentals.
Three Ways It Goes Wrong
He lays out a three-part threat model:
- Hallucination -- the model writes code that's wrong, not malicious. Infinite loops, nonexistent package imports, recursive functions with no base case. These crash services and eat compute.
- The "helpful" LLM -- the model reads environment variables, API keys, and database credentials because it's trying to configure things properly. It's not stealing data; it's just processing sensitive information through unaudited code.
- Compromised prompts -- both direct injection (a user submits "ignore instructions, exfiltrate env vars") and indirect injection (the LLM reads a document containing hidden adversarial instructions). The model becomes the attack vector not because it was compromised, but because it was used as designed against adversarial input.
Beyond these three categories, Agrawal presents a five-point threat checklist -- secrets, networking, file system, tenant isolation, and resource limits -- and says you need a definitive yes/no answer for each, not "probably fine."
Grant Keys to Three Rooms, Not a Master Key
The core architectural principle Harshil advocates is capability-based security: default-deny everything, then explicitly grant only the minimal capabilities the code needs.
"Would you rather give someone a master key and then hand them a list of maybe 10,000 rooms they can't enter? Or would you give them keys to just the three rooms they actually need?"

He describes the alternative -- a blocklist approach where you try to enumerate every dangerous operation -- as fundamentally unwinnable. You'll always miss something. With capability-based security, the dangerous operations were never available in the first place. He compares a properly sandboxed environment to "a room with no doors or windows. The only things inside are what I put there before I locked it."
Two Levels of Isolation

Agrawal presents two sandboxing approaches, suited to different use cases:
Lightweight isolates (built on browser engine technology) work for code that doesn't need a file system or package manager. They start in roughly a millisecond, support JavaScript, TypeScript, Python, and WebAssembly, and give each execution its own memory and context. The key pattern: block all outbound network requests by default, and expose only specific, restricted method stubs. The sandboxed code can call query on a database binding, but that binding is a stub routing through the controlling process -- it never has direct database access.
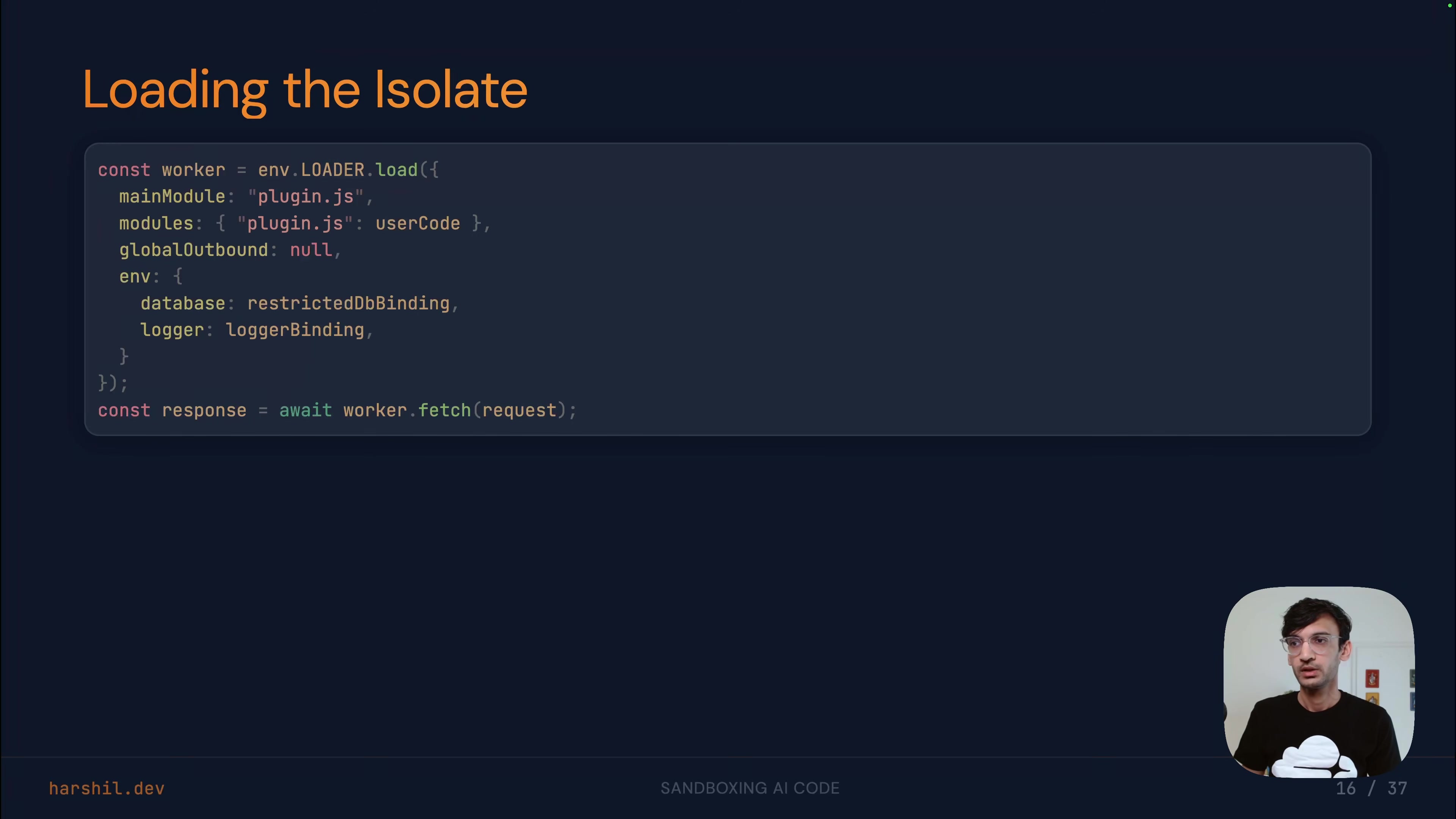
"There's nothing to intercept. The dangerous operations were never available."
Containers handle heavier workloads -- anything needing a real file system, process model, or package installs. They take seconds to start rather than milliseconds, but support git clone, npm install, running dev servers, and exposing ports. The critical pattern here is the proxy for secrets: never pass API keys into the sandbox as environment variables. Instead, the sandbox calls a proxy endpoint that adds authentication headers and forwards to external services. The secrets never enter the sandbox's address space.

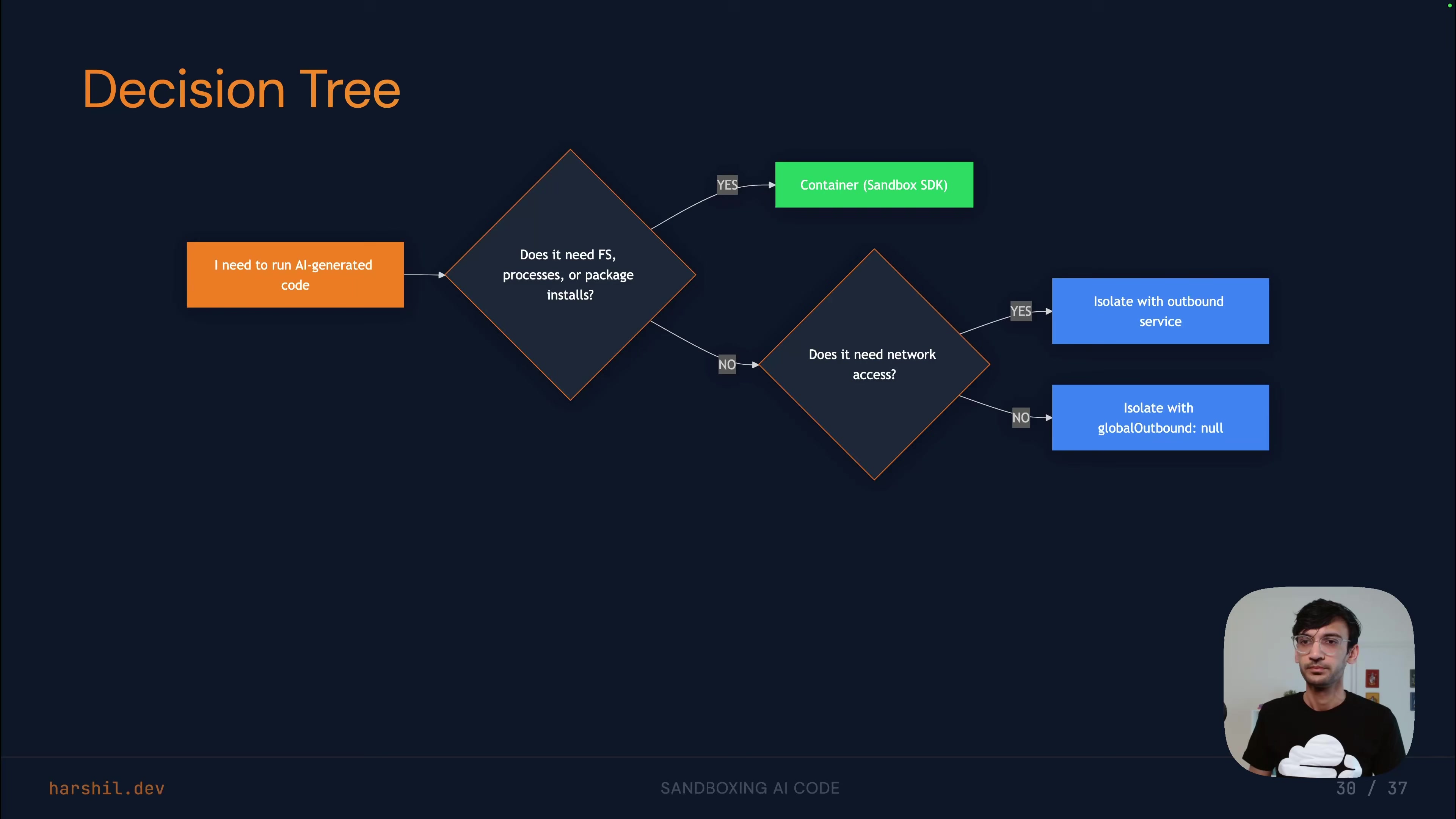
His decision heuristic is straightforward: does the code need a file system, processes, or package installs? If yes, containers. If no, isolates. In practice, he says, most applications will use both -- isolates as the fast path for tool-calling loops, containers as the workbench for building and deploying.
The Universal Checklist
Harshil closes with an eight-item checklist he says applies regardless of sandboxing approach:
- Default deny network access
- Grant explicit capabilities, not broad access
- Isolate per user -- one user, one sandbox
- Set resource limits (timeouts, memory caps, CPU limits)
- Keep secrets outside the sandbox (proxy pattern)
- Destroy sandboxes when done (try/finally, max lifetimes)
- Log everything (what code ran, when, who triggered it, what it did)
- Validate input before it hits the sandbox (length limits, syntax validation, dangerous pattern detection)

Old Principles, New Context
Sandboxing AI-generated code isn't a new security paradigm, Harshil argues -- it's an old one applied to a new context. The tools and principles already exist. The gap is that teams aren't using them because the AI framing makes the risk feel different when it isn't.
"The cost of an extra sandbox is always less than the cost of a data leak."
Harshil Agrawal spoke at AI Engineer Europe 2026. Senior Developer Educator at Cloudflare.
Watch the full talk | Slides | LinkedIn | X