
The Real Problem Is the Six Minutes After the Call
Dippu Kumar Singh (LinkedIn), Leader of Emerging Technologies at Fujitsu North America, presents a talk that starts where most AI discussions stop. Most generative AI demos assume clean text input. In a contact center, the data starts as messy, overlapping, emotionally charged audio -- and the engineering challenge isn't transcription. It's what happens after the call ends.
"We cannot hire more people, we have to fundamentally engineer the stress out of the workflow."
The After-Call Work Problem
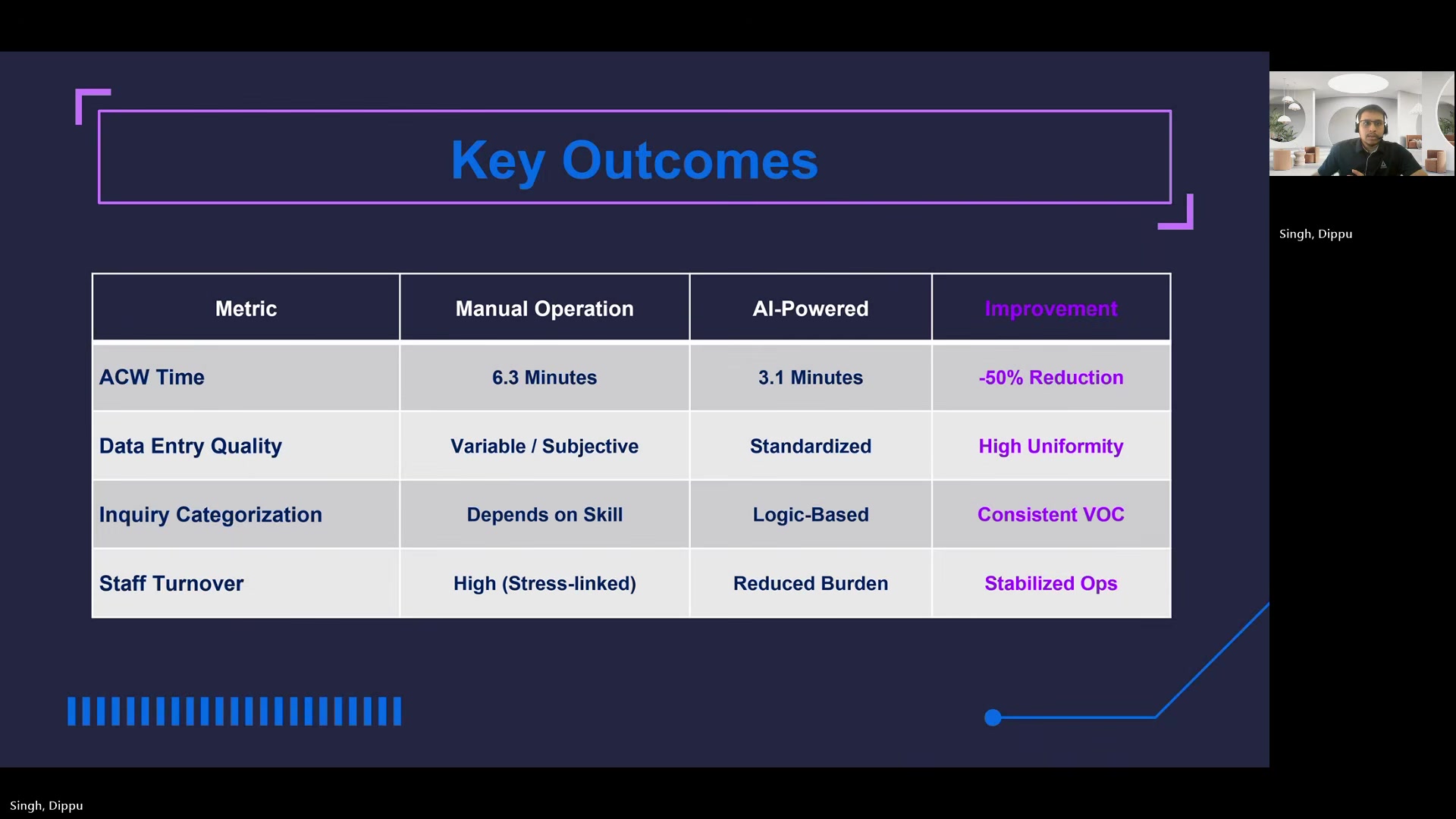
Singh's central reframe is about where the ROI actually lives. He shares internal baseline data showing the average contact center call lasts about 6.5 minutes -- and the post-call administrative work takes another 6.3 minutes. Operators spend nearly half their working hours on data entry, not talking to customers.
That near 1:1 ratio between talk time and paperwork creates a stress-turnover spiral. Operators burn out. Attrition rises. And as Singh argues, hiring more people doesn't fix a structural problem.

The pipeline he describes isn't designed to replace the operator. It's designed to auto-populate structured output that the operator validates with a quick visual check and a confirm click -- turning a 6.3-minute writing task into a seconds-long review task.
Four Stages of the Pipeline
The system Dippu describes is a four-stage architecture deployed in a high-volume contact center.
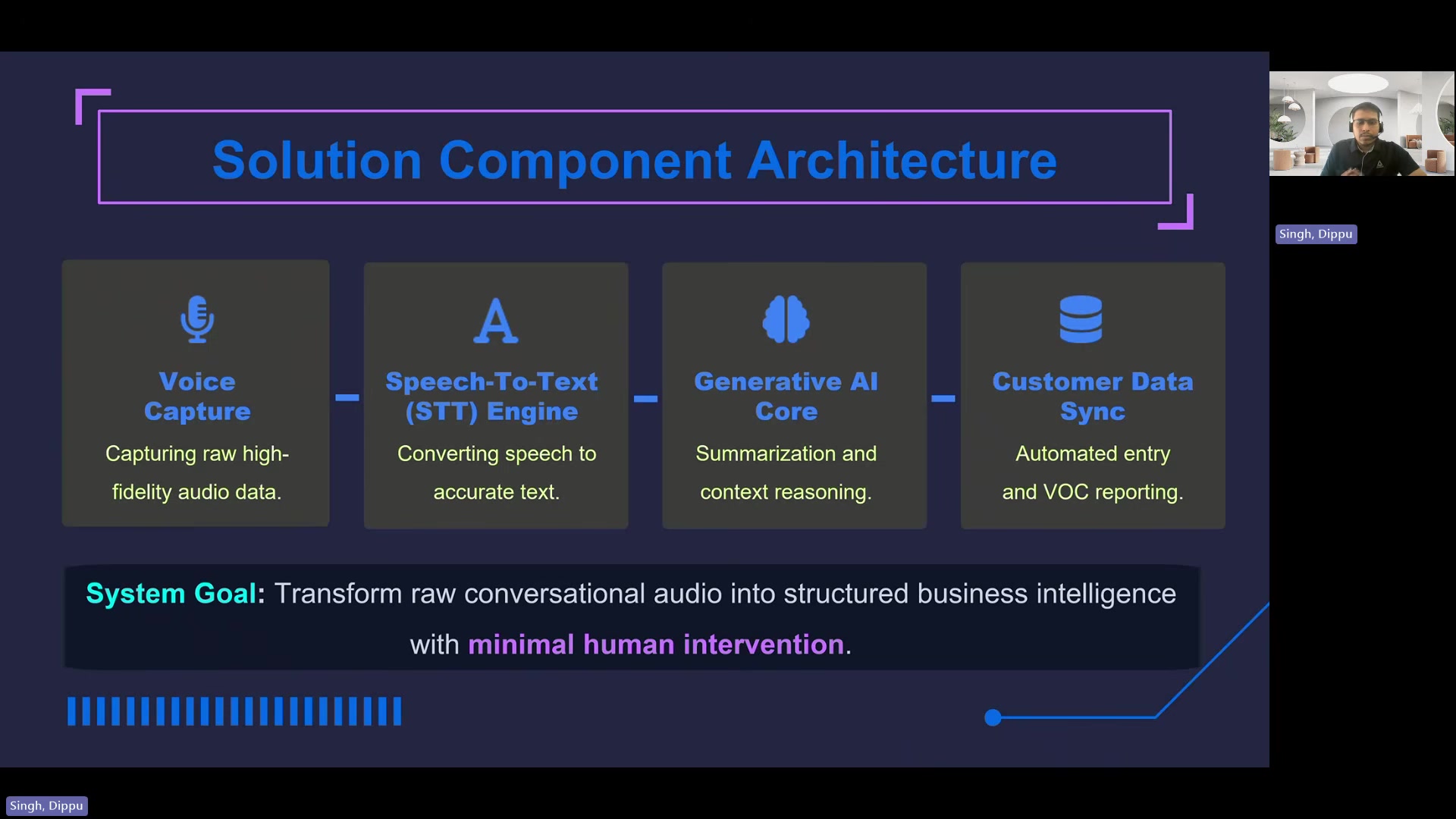
Voice Capture handles real-time audio intake with noise filtering and level normalization. The critical detail here is stereo channel separation -- isolating the agent on one channel and the customer on the other.
"If you mix them into a single mono track, overlapping with each other, the AI will struggle to figure out who said what and thereby ruining the entire downstream summary."
PII masking happens at this stage too. Credit card numbers and passwords are stripped from the audio buffer before anything reaches the LLM.
Speech-to-Text converts the cleaned audio. Singh says the STT accuracy needs to exceed 90% for the downstream AI to function. Domain-specific dictionaries help -- distinguishing "term life" from "turn right" in an insurance context, for example. Post-processing handles inverse text normalization, so spoken "five thousand dollars" becomes "$5,000" before entity extraction.
Generative AI Core is structured in three layers. An orchestration layer uses few-shot prompt libraries rather than open-ended "summarize this call" instructions. A reasoning layer classifies the call against a predefined list of categories (cancellation, new application, claim status) and outputs its reasoning. A trust layer handles token optimization for latency and automated hallucination checks.

Customer Data Sync maps the LLM's JSON output to CRM fields via an API gateway. The operator sees the AI-generated summary auto-populated on screen, makes any corrections, and confirms.
Why "Just Summarize" Doesn't Work
One of the more concrete points Dippu makes is about prompt design. He argues that asking an LLM to summarize a call produces a messy narrative paragraph -- not something you can feed into a CRM.
The alternative: structured few-shot prompts that instruct the LLM to output separate bullet-point lists -- one for customer inquiry, one for operator actions. The model receives a predefined list of call reasons and must classify against them while showing its work.
"This strict formatting is what turns an unstructured conversation into a database-ready asset."
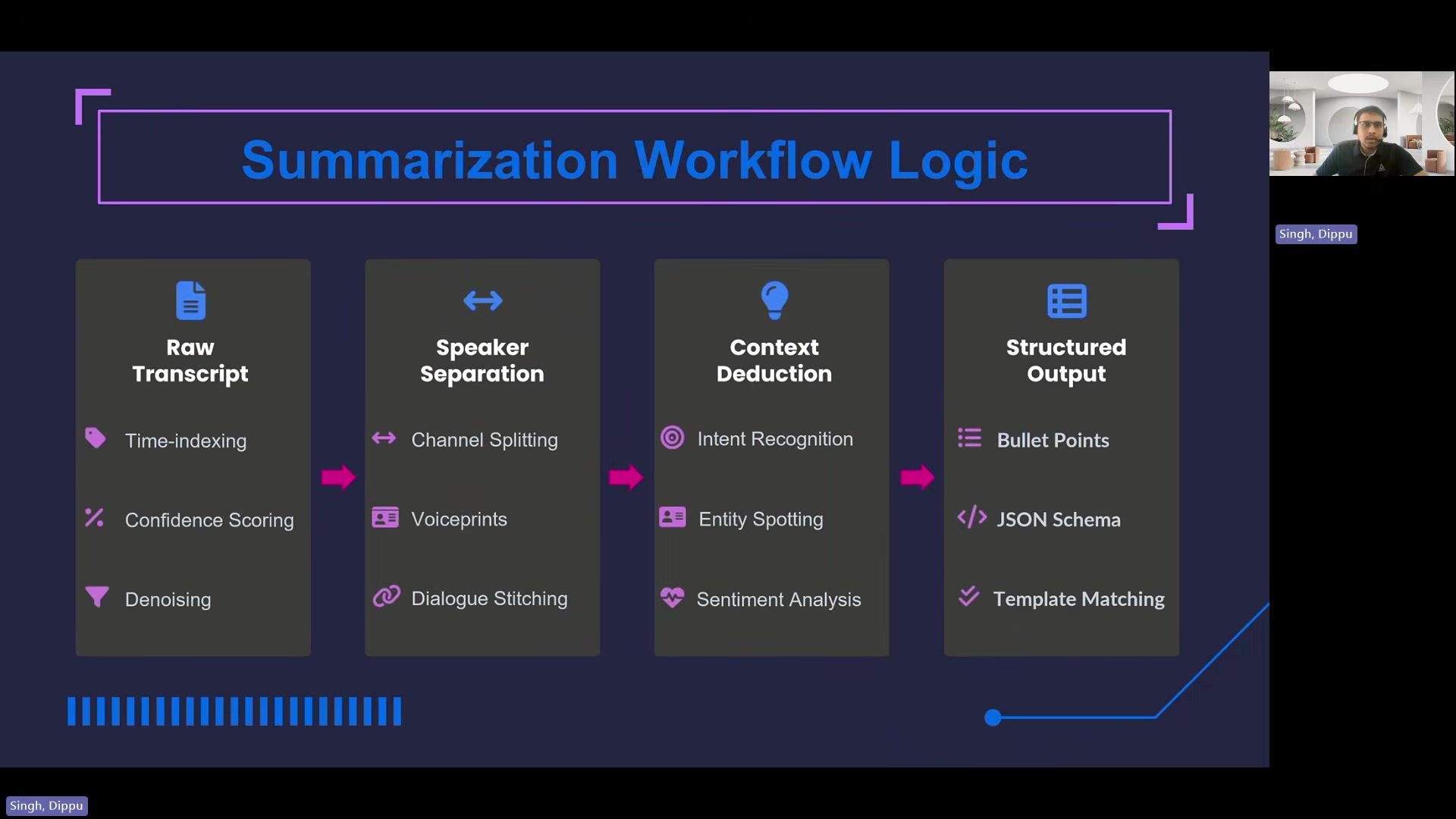
This is where the audio quality decisions upstream pay off. Speaker separation means the LLM can distinguish customer intent from operator chit-chat. Without it, the structured extraction falls apart.
The Results
Singh reports that after-call work dropped to 3.1 minutes -- roughly a 50% reduction. Across what he describes as a 500-seat operation handling thousands of calls per day, that translates to what he characterizes as the equivalent of reclaiming dozens of full-time headcounts in productivity.
Structured data from the pipeline also flows into BI dashboards that aggregate voice-of-customer patterns and auto-flag candidates for new FAQ entries -- a secondary benefit that turns call data into a strategic asset.
What Comes Next
Dippu closes with the argument that this kind of pipeline transforms contact centers from high-stress call centers into what he calls "intelligence-gathering engines."
"By applying these rigorous engineering techniques to the messy audio data, we can definitely transform the contact centers from call centers of high stress into highly efficient intelligence-gathering engines that protect their workforces."
Dippu Kumar Singh spoke at AI Engineer Europe 2026. Leader of Emerging Technologies (Apps) at Fujitsu North America.