
Fitting the Model Isn't the Same as Running It Well
Mozhgan Kabiri Chimeh (LinkedIn), a developer relations manager at NVIDIA, opened her AI Engineer Europe talk with the pain point that drives most AI developers to the cloud: you either run out of memory or you don't have the right software stack. The result is that development iteration speed depends on shared infrastructure, where your work gets scheduled against everyone else's compute jobs.
Her talk walks through benchmarking open-source models from 1.5 billion to 14 billion parameters on a local workstation, with a focus on the trade-offs between throughput, latency, and quantization format. It's a data-driven argument for when local inference makes sense -- and what actually determines whether it's viable.
"This isn't a theoretical talk, it's a data-driven journey through the trade-offs of modern AI infrastructure."
Memory Capacity Is Not Memory Bandwidth
The central insight Kabiri Chimeh presents is a distinction that's easy to overlook. A workstation with 128 GB of unified memory can fit models up to roughly 200 billion parameters. But fitting a model into memory is not the same as running it at useful speeds.

Throughput is governed by how efficiently the system moves data through memory, not just how much it can hold. She argues that this is where most local inference setups fall short -- developers load a model, confirm it runs, and then discover the tokens-per-second rate makes interactive use impractical.
"Memory capacity is not the same as memory bandwidth."
Quantization as the Decisive Lever
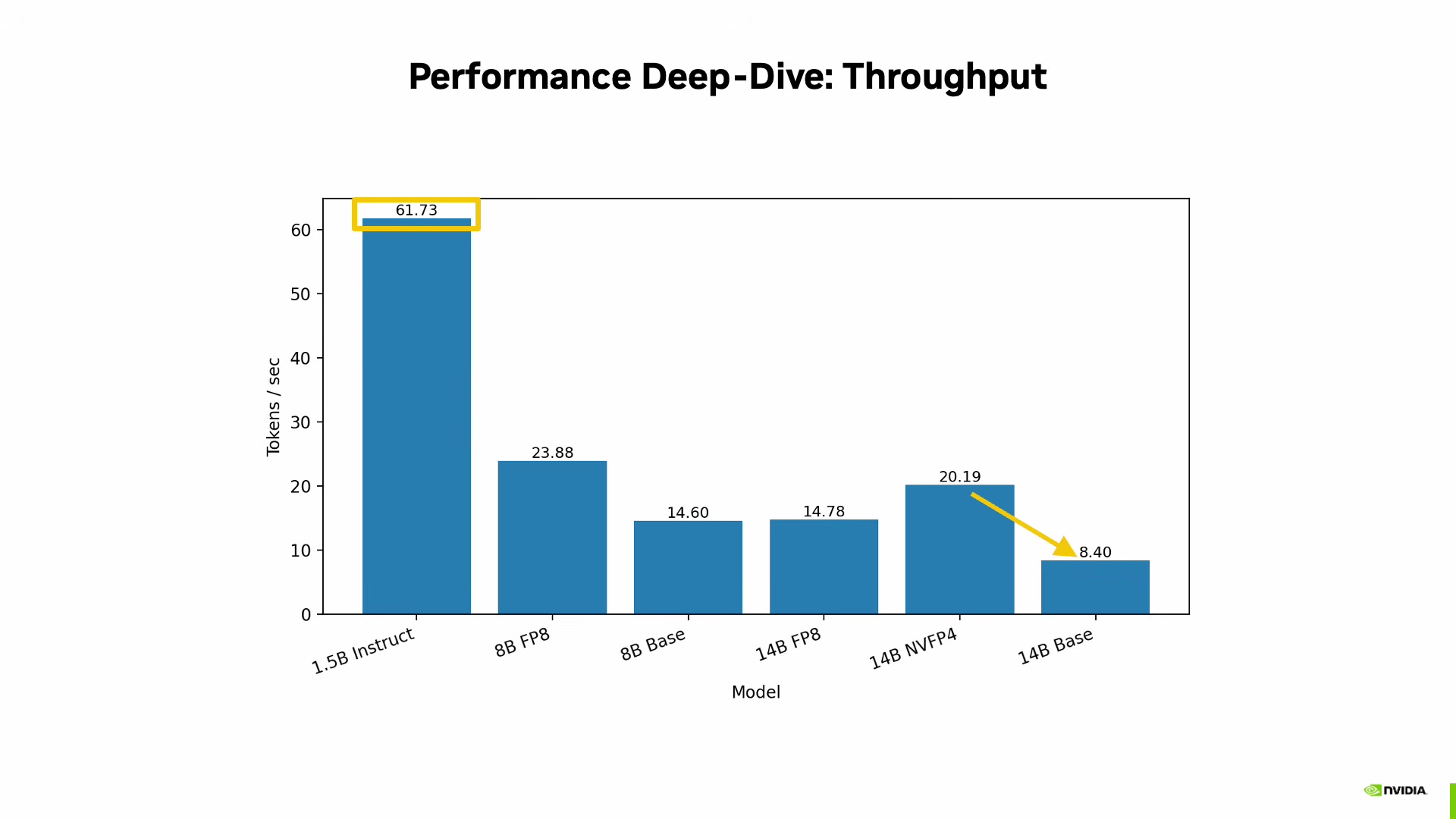
This is where Mozhgan's benchmarks get interesting. She tested the Qwen model family at different sizes and precision formats, and the results show that quantization format choice matters as much as the hardware itself.
The headline numbers for a 14 billion parameter model:
- Base (unquantized): 8.40 tokens/second
- 4-bit quantized (NVFP4): 20.19 tokens/second
That's a 2.4x improvement from quantization alone -- on the same hardware, with the same model. For context, she notes that 20 tokens per second exceeds average human reading speed, which puts it in the range of viable interactive use.
At the smaller end, a 1.5 billion parameter instruct model hit 61.73 tokens per second. The pattern is clear: model size sets the ceiling, but quantization determines whether you're anywhere near it.
"On Blackwell hardware, the choice of quantization format is just as important as the hardware itself."
She describes 4-bit floating point quantization as effectively increasing "intelligence per byte" -- allowing a 14 billion parameter model to feel as responsive as a much smaller one.
Benchmarking That's Worth Reproducing
Mozhgan doesn't just present numbers -- she walks through the methodology in detail, which is arguably the most transferable part of the talk. Her benchmarking harness follows a strict protocol:
- Environment isolation via Docker containers
- Three mandatory warm-up runs before any measurement
- Background GPU metrics logging at one-second intervals
- Each run generates a unique directory with timestamp and sanitized model ID
- Full capture of model endpoint response and metrics
- Versioned artifacts containing metadata and benchmark results

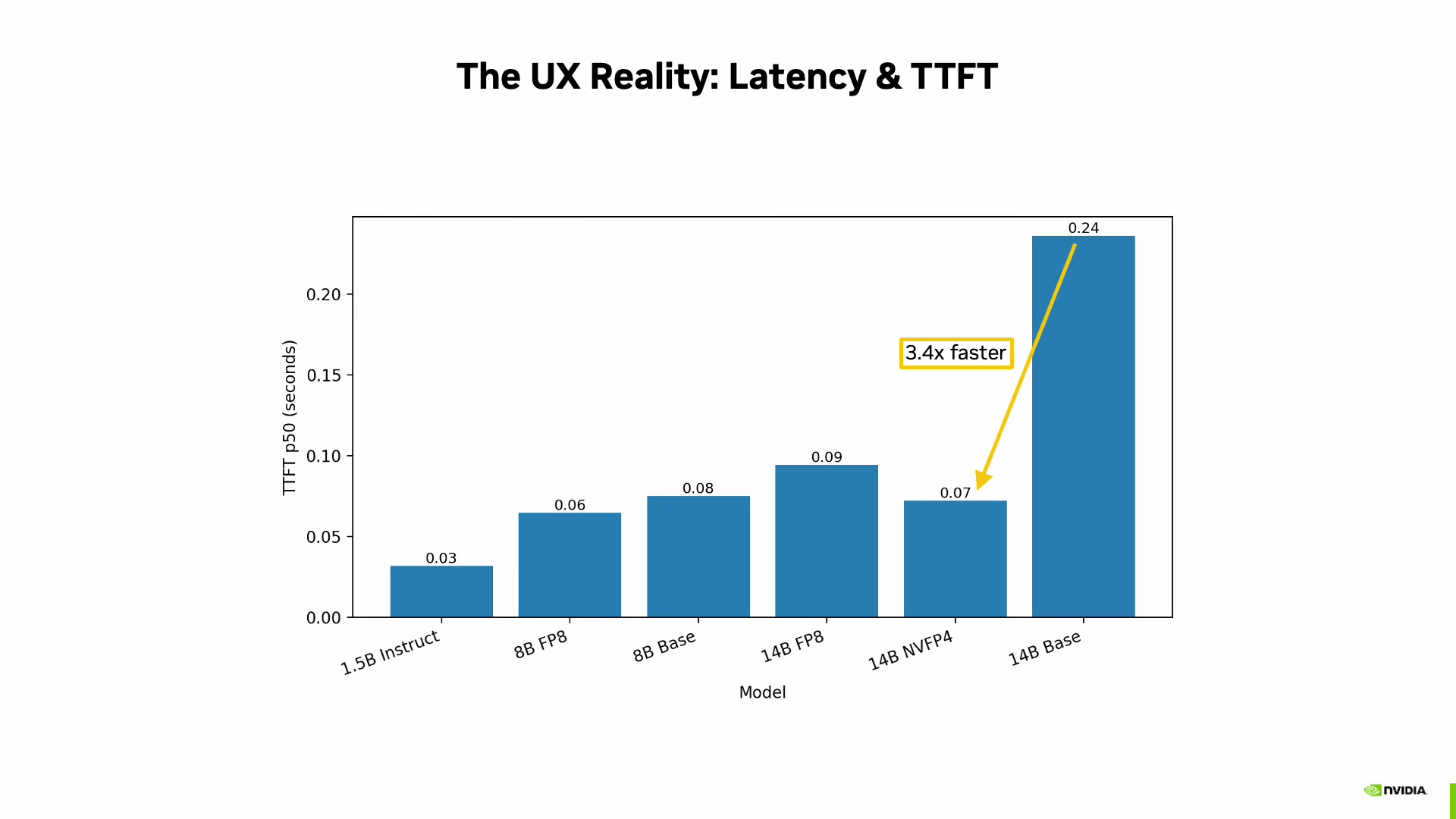
She measures two key metrics: completion tokens per second (raw throughput) and time to first token (TTFT), which captures user-perceived responsiveness. The TTFT measurement uses explicit streaming response handling, timestamping the first chunk from the model server.
The TTFT results reinforce the quantization story: the 4-bit quantized 14B model is 3.4x faster to first token than the unquantized version.
When Local Compute Is the Right Choice
Mozhgan frames local inference not as a replacement for the cloud but as a complement. She identifies three use cases where it makes the most sense:
- Steady-state workloads -- predictable inference demand that doesn't need elastic scaling
- Privacy-sensitive data -- when data governance means nothing leaves the building
- Rapid prototyping -- fast iteration cycles without waiting for shared infrastructure
"The key idea here is not replacing the cloud, but bringing powerful AI development closer to the developer."
The software stack she demonstrates uses the same serving framework (vLLM) and containerized environment that runs in data center deployments. Her point is that workflows developed locally can move to larger infrastructure without rearchitecting -- the iteration happens close to the developer, and the scaling happens later.
The Takeaway
Kabiri Chimeh's argument comes down to a practical framework: if your model fits in memory, the next question isn't whether it runs -- it's how fast. Quantization format is the lever that determines whether local inference is a viable development workflow or a frustrating bottleneck. Match your quantization to your use case, benchmark rigorously, and scale out only when the workload demands it.
"Run locally, iterate quickly, and when ready, scale to data center or cloud."
Mozhgan Kabiri Chimeh spoke at AI Engineer Europe 2026. Developer relations manager at NVIDIA.