
RAG Isn't Dead, You Just Need a Better Starting Point
Phil Nash (X, LinkedIn), a developer relations engineer at IBM, opened his AI Engineer Europe talk by taking aim at the "RAG is dead" discourse. His counter is simple: if every business had less than a million tokens of data, maybe. But they don't, and not everyone wants to pay for a million input tokens on every query. RAG isn't going anywhere -- it's just harder than people think.
"It turns out that RAG is actually hard, and it's hard for different reasons for different projects."
The Problem Isn't the Loop
Phil argues that the basic retrieve-and-generate pattern isn't where teams struggle. The difficulty is everything around it: parsing messy documents (especially PDFs), choosing embedding models, tuning chunking strategies, and adapting search to specific data and user patterns. Every organization's documents and users are different, so there's no universal solution.
His reframe: what's missing isn't a better algorithm but a better starting point. An opinionated-but-flexible baseline built from open-source components -- sensible defaults with every layer exposed for customization. He presented a stack combining three open-source projects (Docling for document processing, OpenSearch for search, and Langflow for orchestration) as one such baseline, currently at version 0.4.0.

Parsing Is the First Hard Problem
The document processing layer uses Docling, an open-source library from IBM Research Zurich. Phil walks through why parsing matters: RAG applications ingest HTML, Markdown, Word docs, slides, spreadsheets, audio, video, and PDFs. Each format has different challenges.
Docling runs multiple processing pipelines depending on file type:
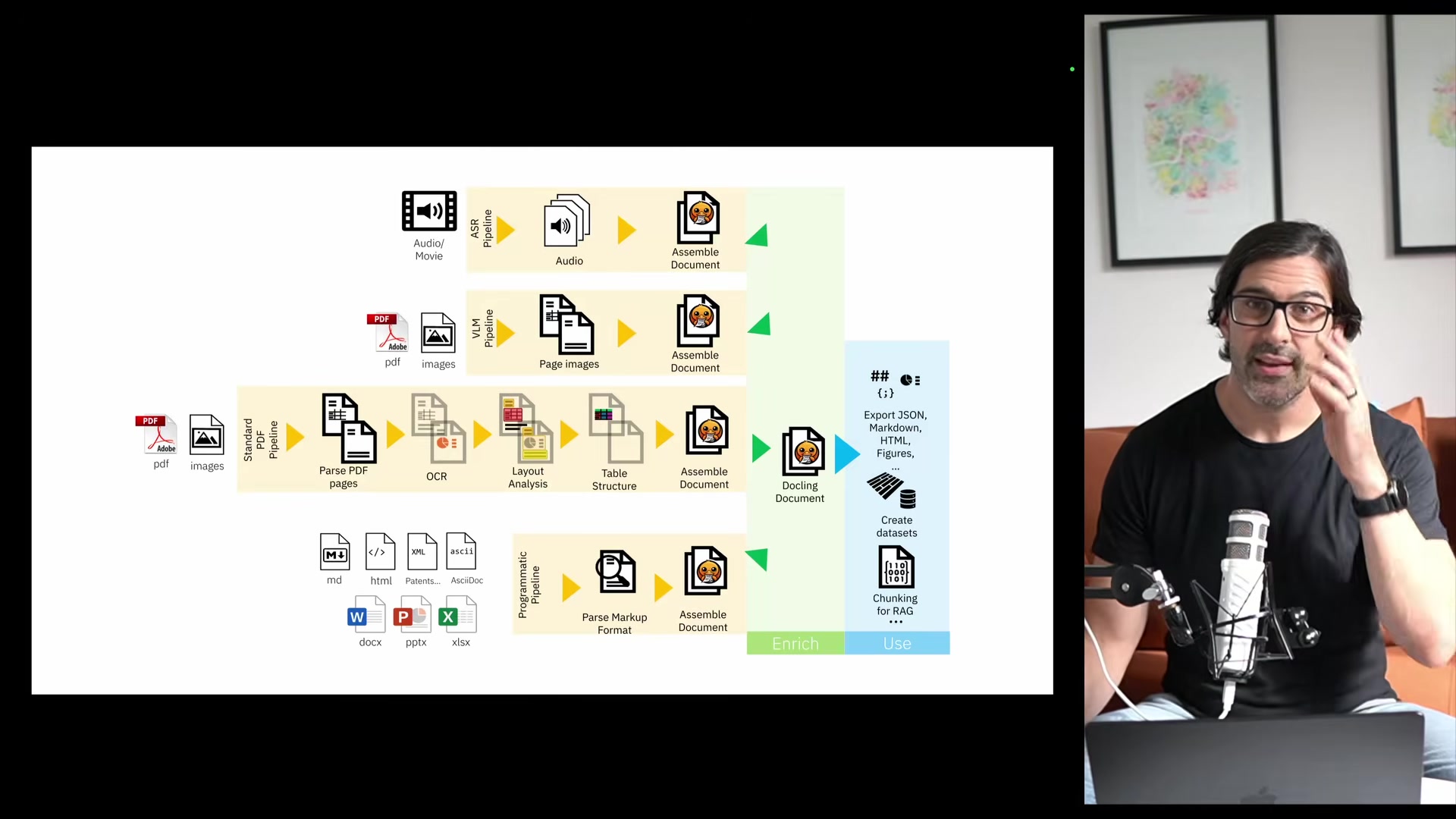
- Simple pipeline -- text extraction and hierarchy for straightforward formats like Markdown and HTML
- ASR pipeline -- automatic speech recognition for audio and video
- Standard PDF pipeline -- a collection of small focused models for layout analysis, table extraction, and image extraction, with optional OCR for scanned documents
- VLM pipeline -- a 258-million-parameter vision model (Granite Docling) that extracts everything in a single pass
All of these produce an intermediate representation -- an XML-like format called DocTags -- that can be converted to Markdown, HTML, or JSON. The chunker then uses the document's parsed structure rather than arbitrary character counts, which Nash presents as a meaningful improvement over naive chunking strategies. The whole thing runs offline, which matters for air-gapped environments.
Search Beyond Vectors
The retrieval layer uses OpenSearch, the open-source Elasticsearch fork. Nash's point here is that vector search alone isn't enough -- hybrid search combining vectors and keyword matching gives better results out of the box.
A few features he highlights:
- Multiple embedding models simultaneously -- useful when migrating between embedding models, though he notes it slows search down
- Configurable filtering and aggregation -- exposed to end users as "knowledge filters" so they can scope queries to specific document sets
- JVector -- a disk-ANN-based vector index plugin that replaces the default HNSW/IVF options. The key property: indexes don't need to fit entirely in memory, and it supports live indexing
Making Retrieval Agentic
The most interesting architectural choice Phil describes is replacing the traditional retrieval pipeline with an agent. Instead of the standard embed-query, top-K, stuff-into-prompt flow, the user's query goes to an agent equipped with search tools. The agent decides what searches to run and how many.
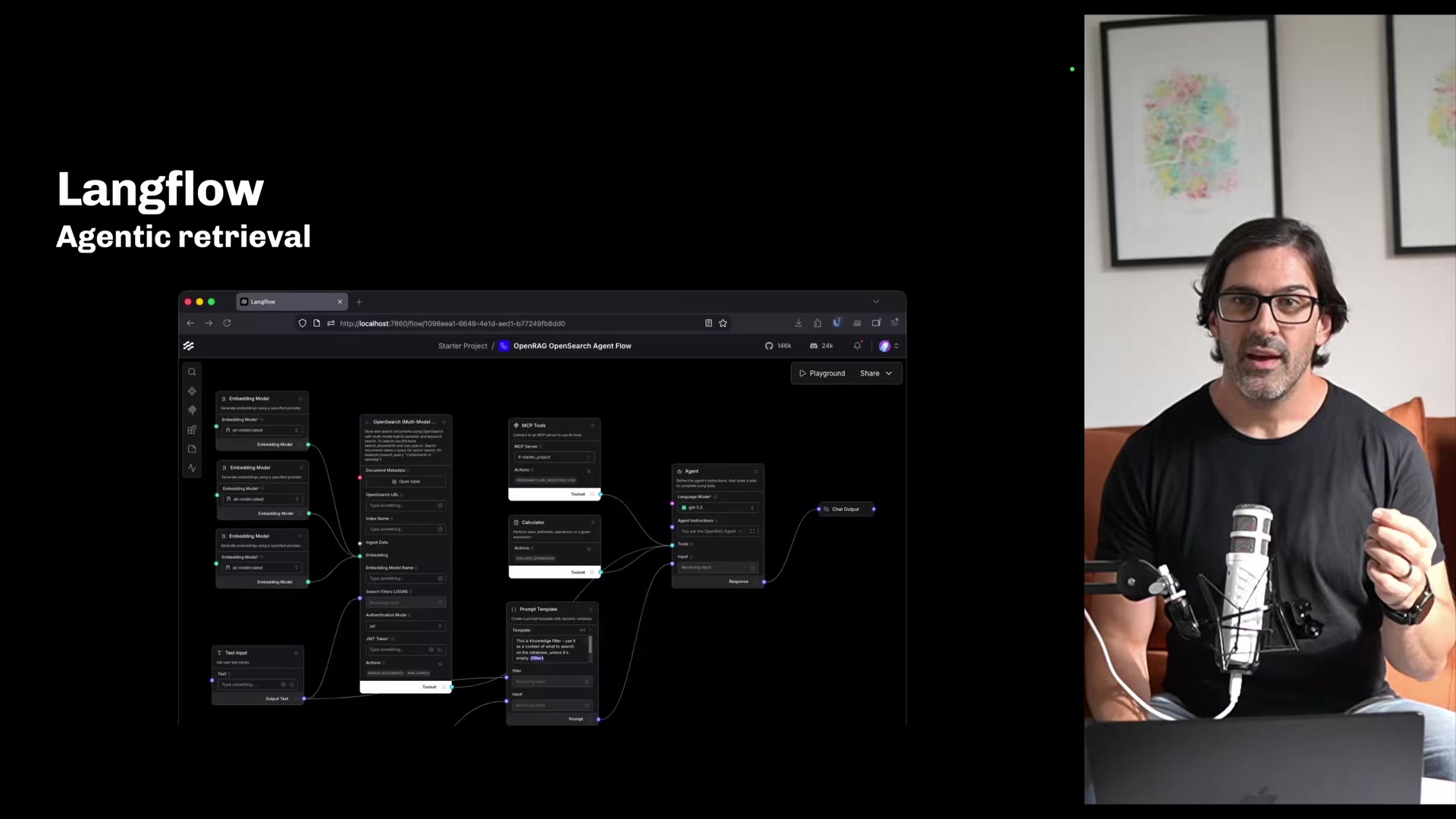
In his demo, the agent has access to an OpenSearch search tool, a calculator, and an MCP-based URL ingester. He demos the generation side running Granite 4 3B locally through Ollama, with Qwen3 Embedding 0.6B handling the embeddings -- also local.
"They're language models, not math models. So a calculator is always useful."
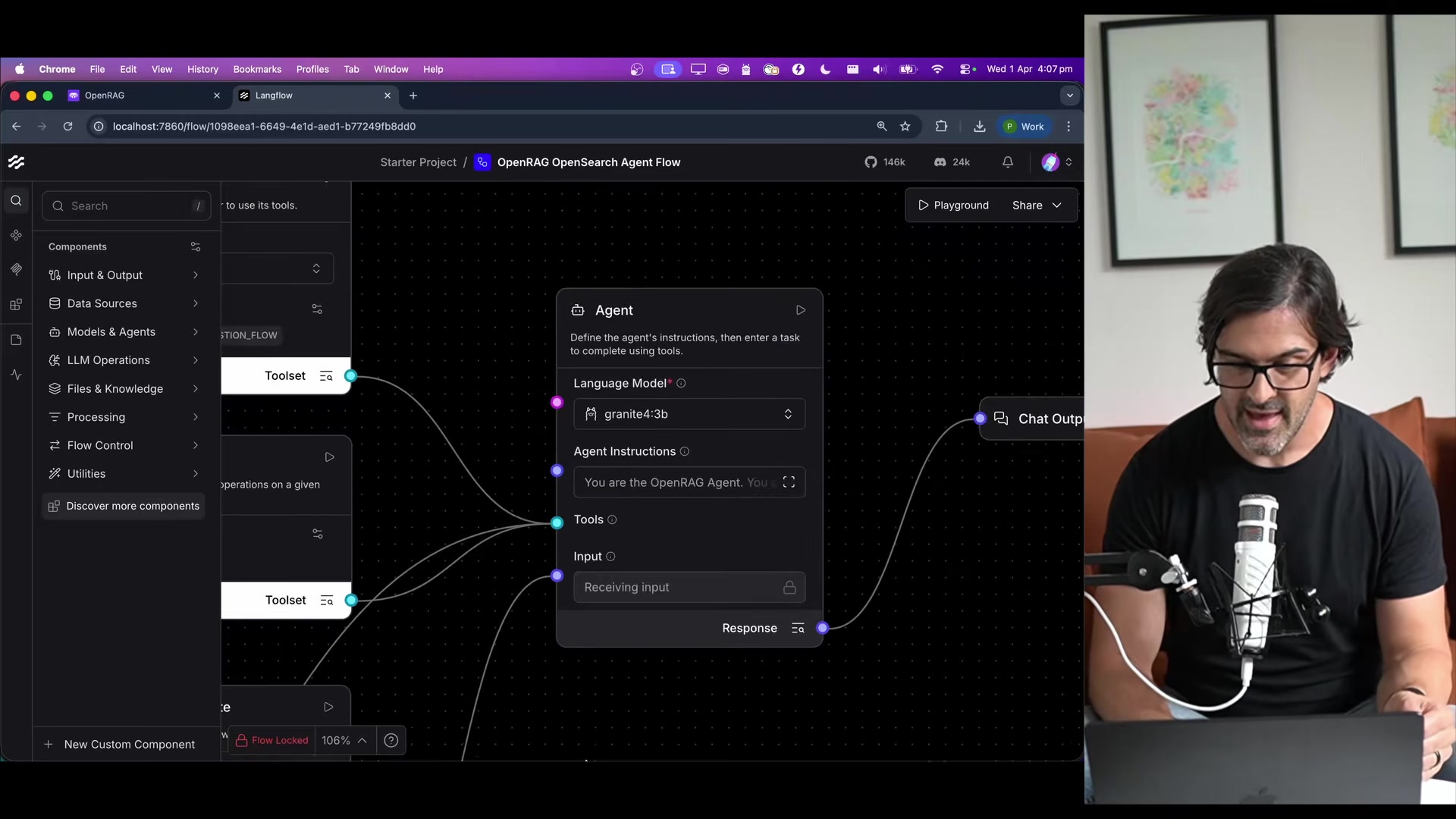
The orchestration layer (Langflow) provides a drag-and-drop visual editor for these flows. Nash demos adding guardrails to the agent pipeline by dragging in components -- the point being that customization doesn't require rewriting code.
Everything Is Swappable
Phil is explicit that the stack isn't prescriptive about model providers. It supports OpenAI, Anthropic, WatsonX AI, and Ollama for both embedding and generation. The demo uses fully local models, but you can swap in hosted APIs without changing the pipeline.
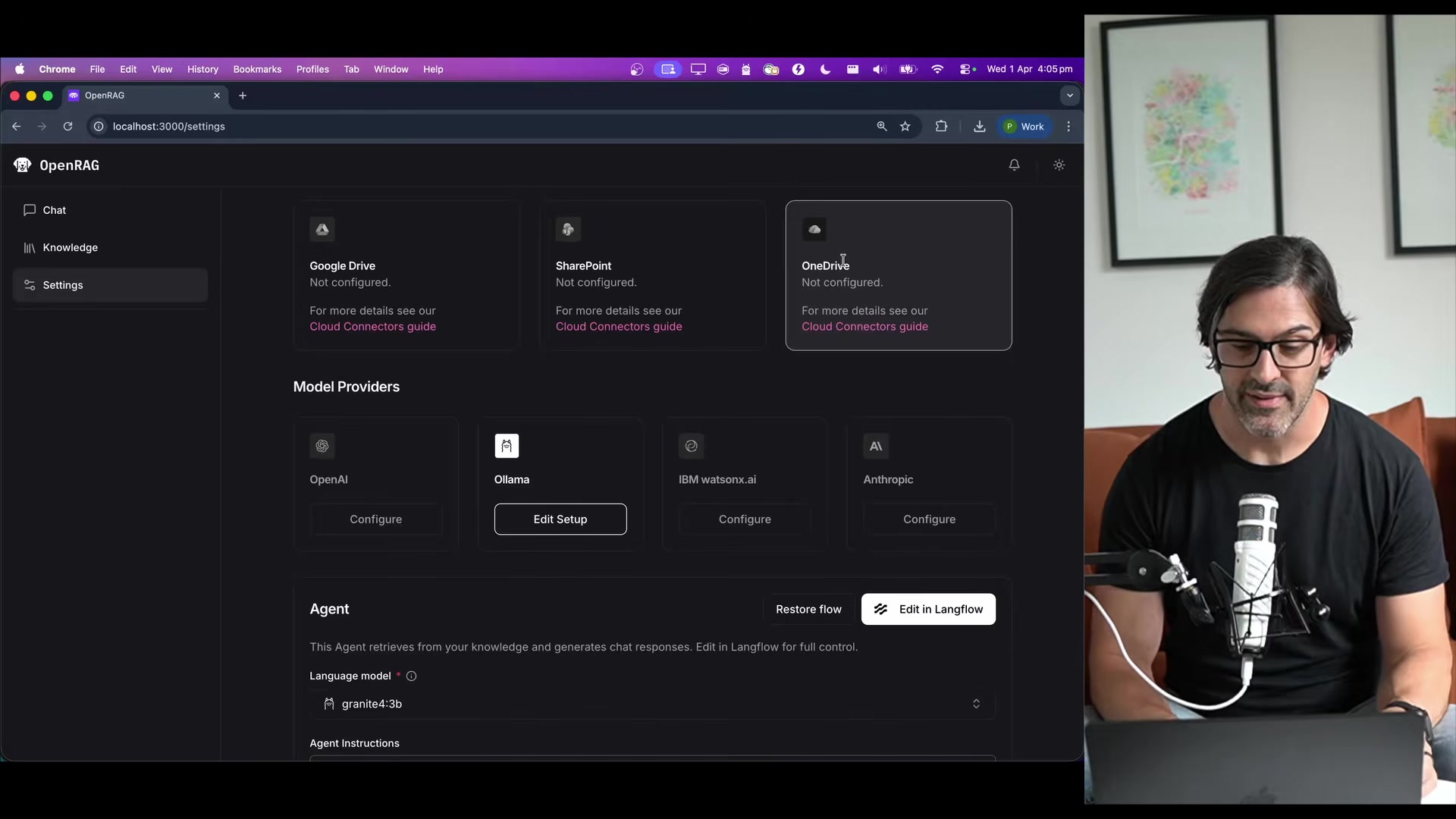
The project also includes cloud connectors for Google Drive, SharePoint, and OneDrive for document syncing, a chat UI with suggested follow-up prompts, and API keys for using the search and agent capabilities in external applications. There's also an MCP server available for handing the stack off to other agents.
The Takeaway
Nash's closing argument is that whether RAG is "solved" depends entirely on your data and your users. The answer isn't a single algorithm -- it's a stack that gives you a strong baseline and lets you tune every layer against your own evaluation criteria.
"Well, that's kind of up to you, to your data and to your users."
Phil Nash spoke at AI Engineer Europe 2026. Developer relations engineer at IBM.
Watch the full talk | OpenRAG on GitHub | Docling | philna.sh | LinkedIn | X