
When Every Team Builds Its Own AI Agent, You Need a Registry
Sonny Merla, Mauro Luchetti, and Mattia Redaelli (Quantyca) opened with a question that any large organization experimenting with AI agents will recognize: what happens when dozens of teams across multiple continents are all building agents independently?
"What happens when you have dozens of teams across three continents, all building AI agents, each one wiring up their own connections, reinventing their own security model, deploying their own infrastructures? You get chaos."
Their answer, built for a global enterprise operating across 26 countries, is a registry-based architecture that makes governance a side effect of deployment rather than a gate before it.
The Problem With Letting Teams Solve It Themselves
Sonny described the familiar pattern: teams build what they need, wire up their own security, deploy their own way. Multiply that across an enterprise and you get no central visibility into what AI tooling exists, no standardized deployment process, and no way to trace which business use cases depend on which models and services.
The challenges, as he framed them, fall into three buckets: maintenance and operations (keeping everything running), governance and compliance (knowing what's deployed and who owns it), and enterprise scaling (making it work across the whole organization without slowing anyone down).
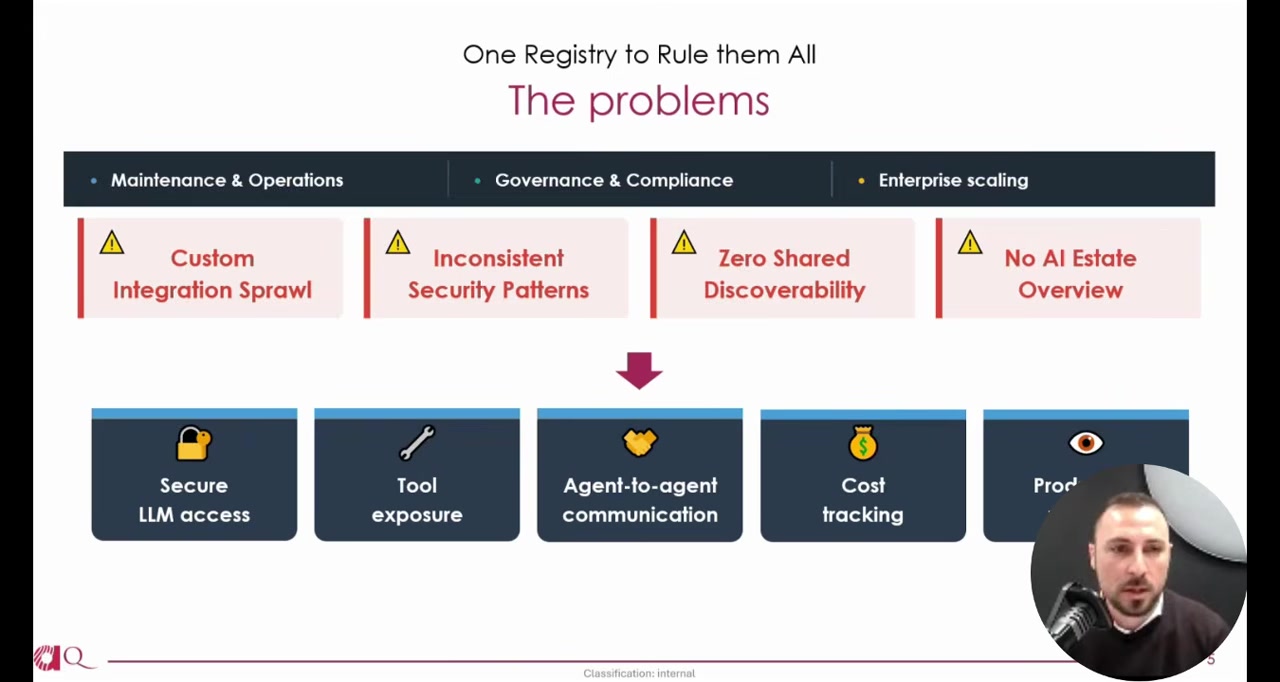
Governance as a Byproduct of Shipping
The core architectural idea is straightforward. Rather than creating an approval process that sits between developers and deployment, they built a system where deploying an MCP server or an A2A agent automatically publishes its metadata to a central registry through CI/CD.
Mauro described it as making agent development "self-documenting." Tag a branch, and a GitHub Action publishes both the Docker image and the metadata -- an agent card for A2A agents, a server.json for MCP servers -- to the registry catalog.
"We want to make easy the life of developers to focus on the business logic inside the use cases, avoiding to reinvent the wheel every time we need to take care about the security, but also the deployment and maintenance of the use cases."
The result is that governance doesn't require extra work from developers. It happens because they shipped.
Three Registries, One Graph
The architecture centers on three interconnected registries.
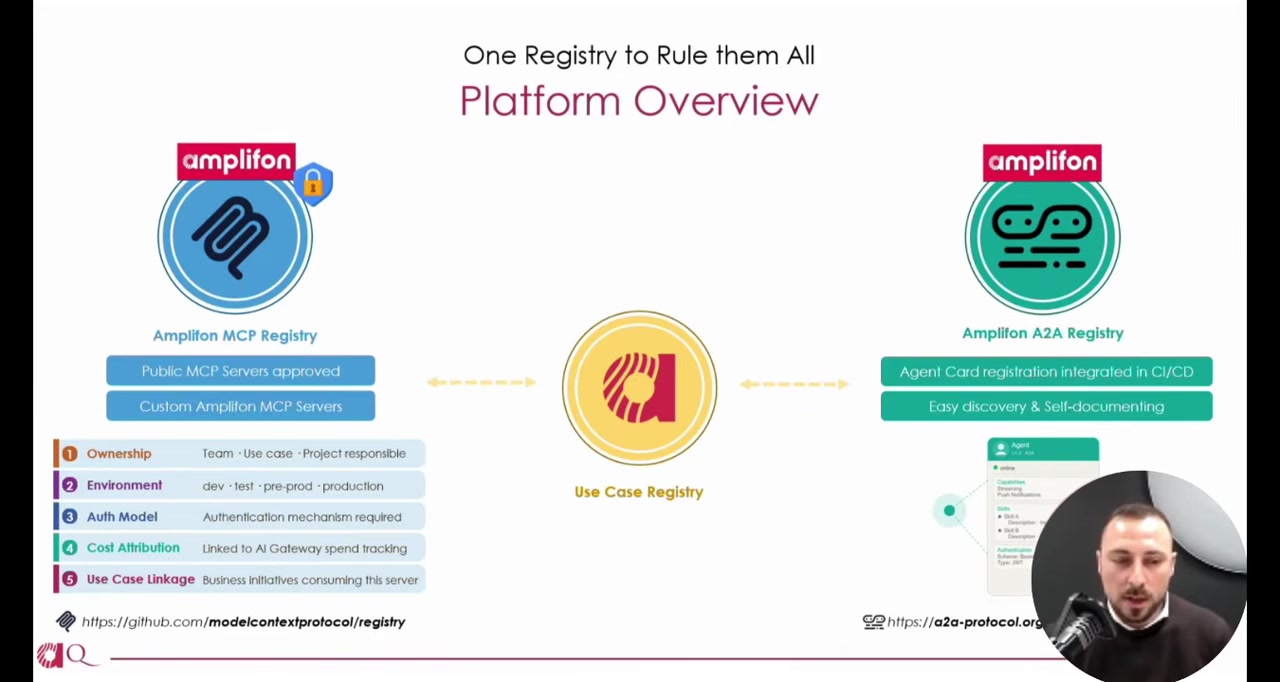
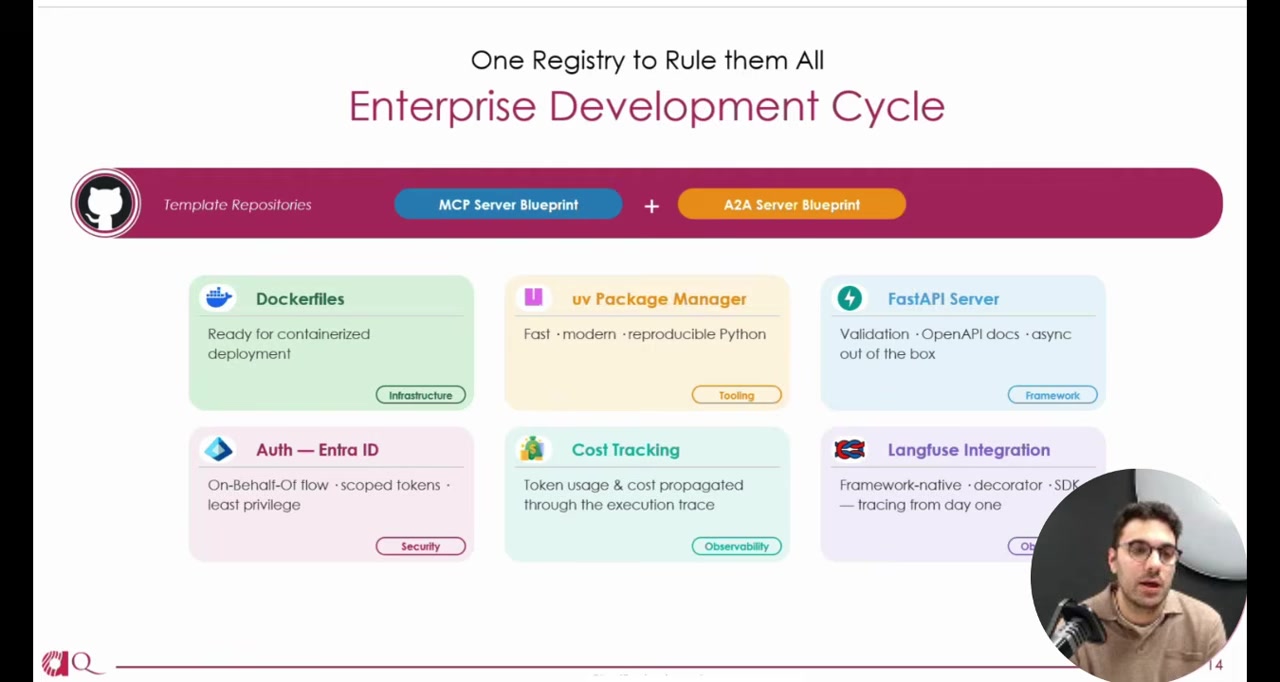
The MCP Registry is a private extension of the open-source MCP registry specification. It contains both custom internal servers and a curated subset of approved public ones. Each entry carries enterprise metadata: ownership, environment, authentication model, and cost attribution.
The A2A Registry is based on agent cards from the Agent-to-Agent protocol. When an agent deploys, its card is automatically published. Other agents and developers can discover it immediately.
The Use Case Registry ties the other two to business context. It maps agents and tools to specific use cases and tracks which AI models each depends on.
Mauro argued this metadata isn't optional decoration:
"These are not simply metadata that are nice to have. This is something that really brings out the impact analysis functionality."
The registries together enable lineage analysis -- tracing the full dependency graph from a use case down through agents, MCP servers, and models. If a model goes down, you can see what breaks.
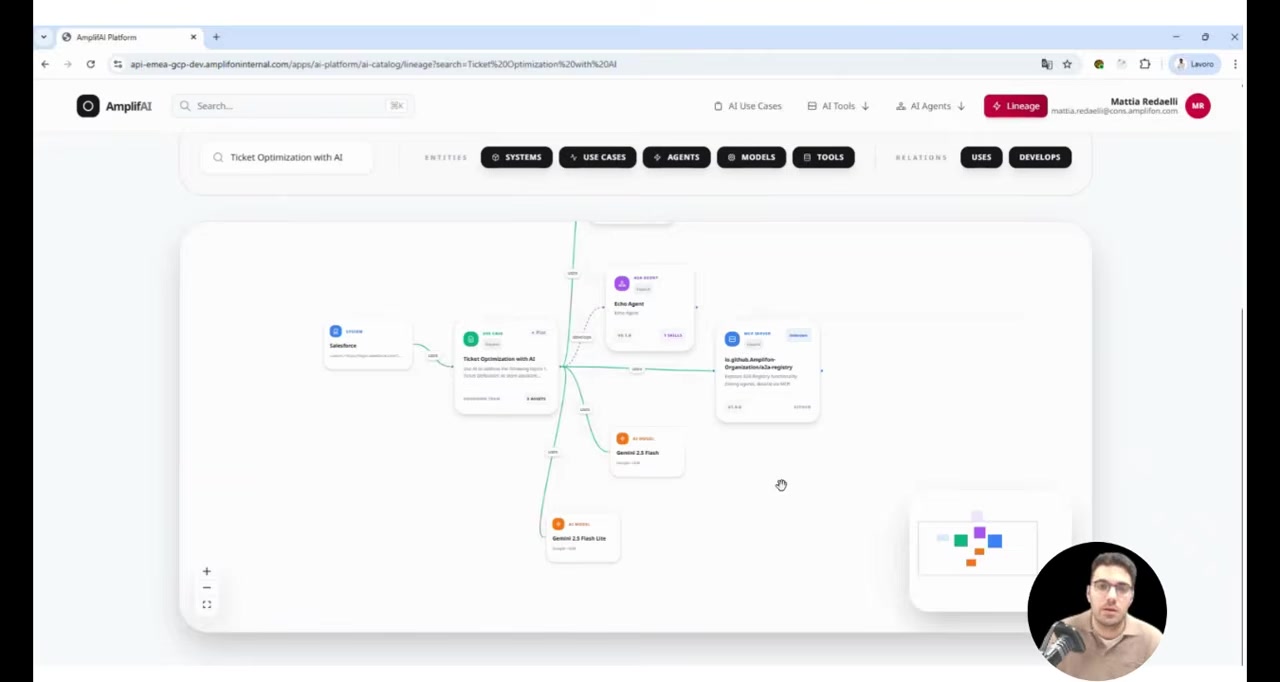
The Platform Layer
Sitting above the registries is a unified AI gateway that handles authentication, per-use-case budgeting, and central auditing of all LLM requests. Sonny described monthly and weekly cost caps that erode as tokens are consumed, giving each use case its own budget envelope.
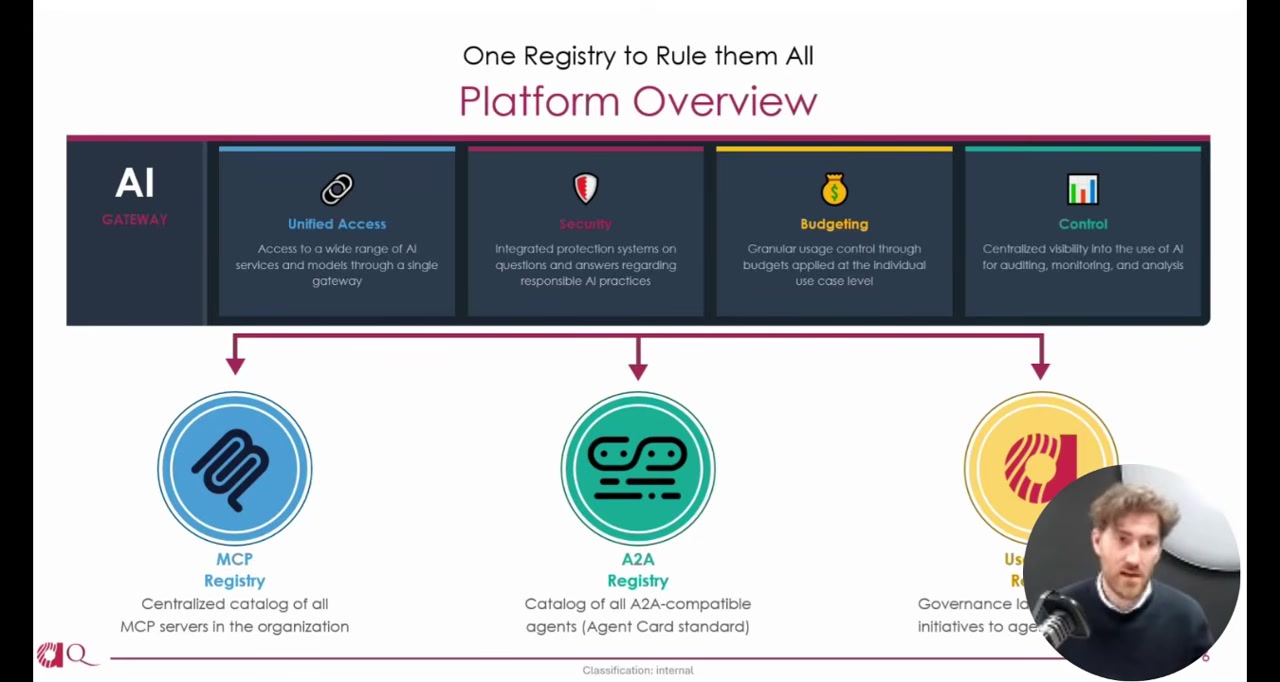
Below the registries, two template repositories -- one for MCP servers, one for A2A agents -- give developers a starting point with authentication, cost tracking, and observability pre-configured. Mattia noted the A2A template is framework-agnostic, using interfaces so teams can implement with whatever agent framework they prefer.
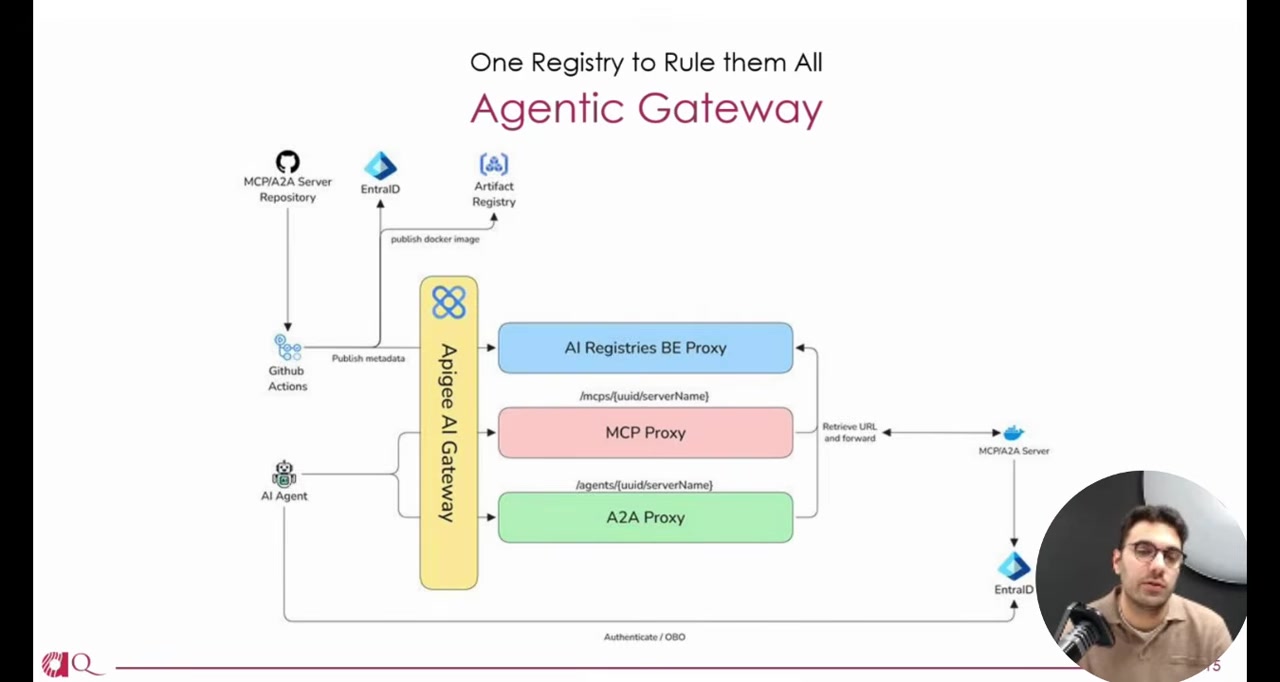
The runtime discovery flow works through an API gateway with proxies that look up backend URLs from the registry catalog. Agents authenticate via a separate header to the actual backend.
Where This Stands
The speakers were transparent that the platform is not yet in production. Mauro noted it is "still in progress," and the demo used sample data. The architectural patterns -- self-registering services, metadata-rich catalogs, lineage graphs -- are well-established in data engineering. The contribution here is applying them specifically to the MCP and A2A ecosystem.
The bet is that as internal MCP servers and A2A agents multiply, the discovery and governance problem will hit every large organization. Building the registry into the deployment pipeline, rather than bolting it on after, is how they propose to keep it from becoming another compliance burden that developers route around.
Visibility First, Control Second
Sonny, Mauro, and Mattia are making a case that the scaling problem for enterprise AI agents isn't technical capability -- it's visibility. If you can't see what's deployed, who owns it, and what depends on what, you can't govern it. And if governance requires extra work, developers won't do it. The registry approach makes the right thing the default thing.
Sonny Merla, Mauro Luchetti, and Mattia Redaelli spoke at AI Engineer Europe 2026. Merla is Global Data Science and AI Manager at Amplifon; Luchetti is AI Center of Excellence Manager and Redaelli is AI Engineer at Quantyca.