
Your LLM Evaluator Is Probably Lying to You
Mahmoud Mabrouk (X, LinkedIn), co-founder and CEO of Agenta AI, opened his AI Engineer Europe workshop with a scenario most teams will recognize: your LLM agent is in production, your observability dashboard looks clean, but customers keep saying the thing doesn't work. The culprit, he argues, isn't the agent -- it's the evaluator. A miscalibrated LLM-as-a-judge gives you false confidence while producing no useful signal.
"You'll find a prompt not very far from this one: 'You'll be given an LLM output, write whether it's a hallucination, make no mistakes.' Now obviously, how the hell would the agent know whether it's a hallucination? If it could, then your app would have worked from day one."
Evaluation as a Machine Learning Problem
Mabrouk's central reframe is that building an LLM-as-a-judge is itself a machine learning problem, not a prompt engineering exercise. The evaluator prompt is a learned artifact that should be optimized against labeled data -- the same way you'd train any model. The quality ceiling of your evaluator, he argues, is determined by the quality of your annotation data and your optimization process, not by how clever your starting prompt is.

This leads to what Mahmoud calls the "holy grail of AI engineering" -- a data flywheel where you optimize your evaluation harness, observe traces in production, add new evals based on edge cases, and repeat.
"The speed in which you move to production or add features is actually the speed in which you can complete this loop."
Four Steps to a Calibrated Judge
Mahmoud's workflow has four stages:
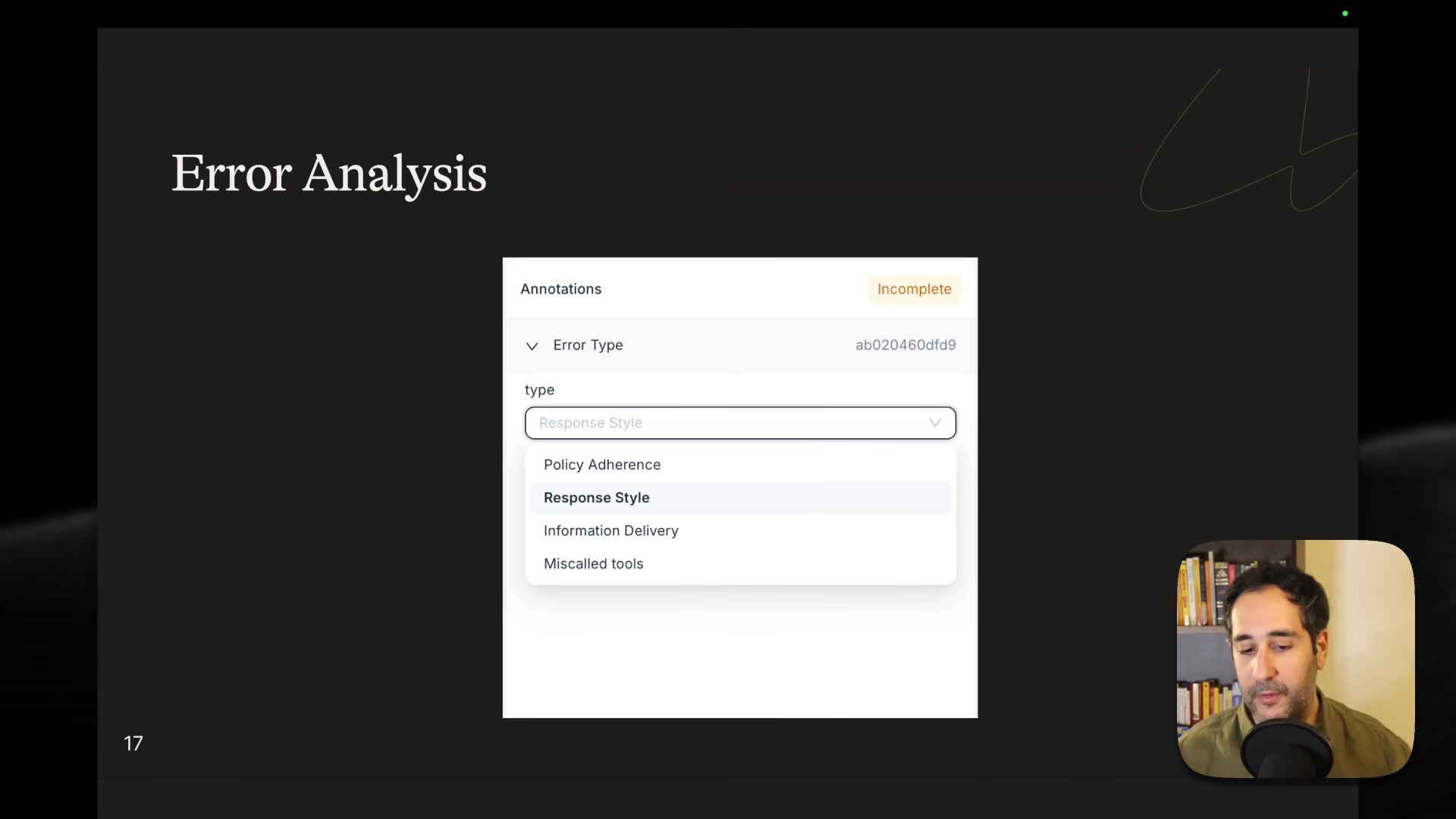
- Metric design -- Define evaluation axes from your specific use case, not from generic libraries. He identified four error types through manual analysis of traces: policy adherence, response style, information delivery, and incorrect tool calls. Each gets its own binary evaluator (pass/fail, not a 1-5 scale). He credits Hamel Husain for articulating this error analysis workflow.
-
Data annotation -- Subject matter experts annotate conversation traces with binary verdicts plus reasoning. Mabrouk stresses the reasoning field is critical -- without it, the optimization algorithm has to independently discover why something failed, which is extremely difficult for complex policy evaluation.
-
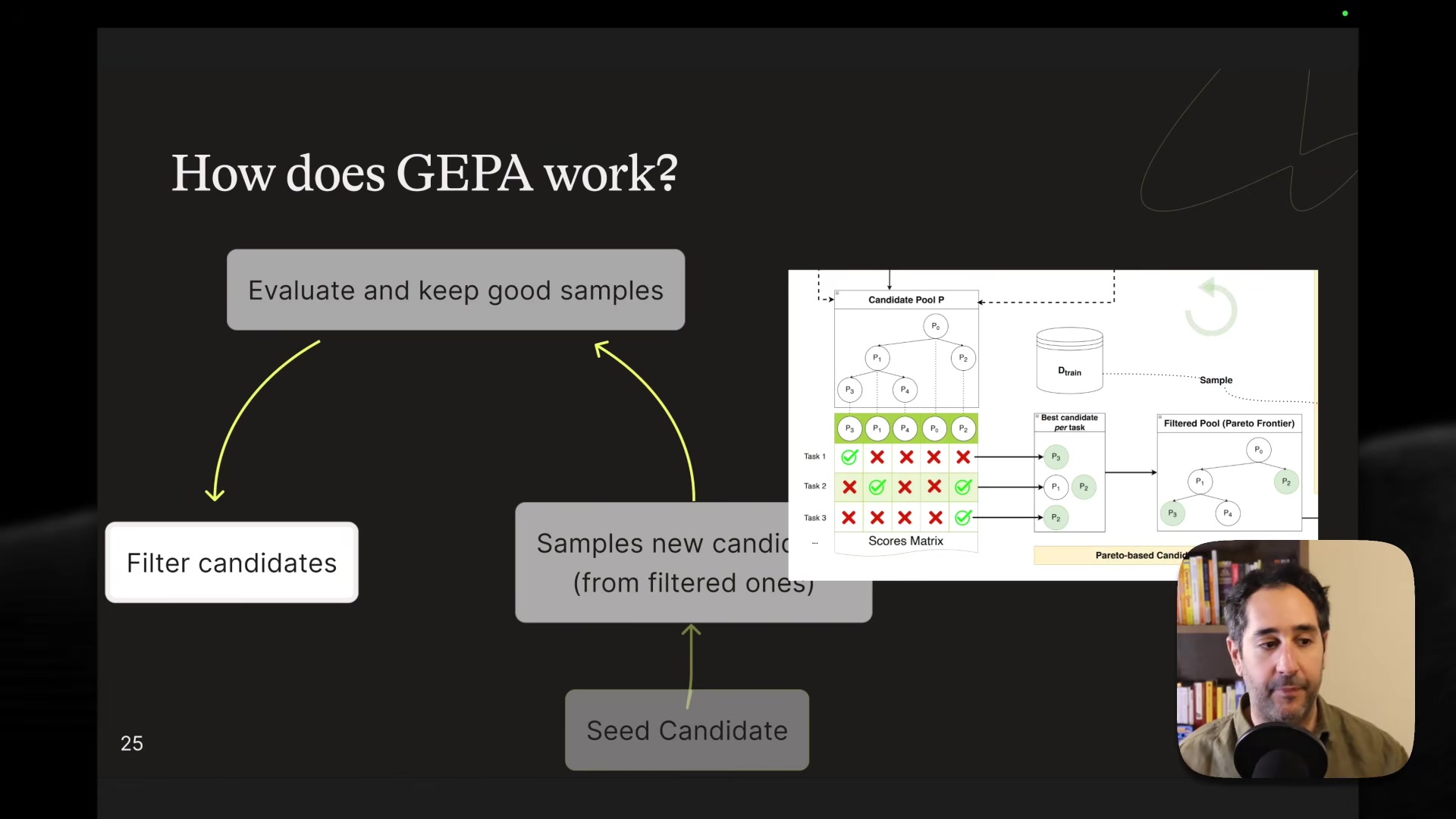
Optimization with GEPA -- GEPA is a prompt optimization algorithm that works like a genetic algorithm. Each iteration samples new candidate prompts (through mutation and merging), evaluates them against mini-batches of training data, then selects the best candidates using a Pareto frontier rather than simple averaging. The Pareto approach maintains diversity -- it picks the best candidate per task before merging into a final prompt.
- Validation -- Evaluate the optimized judge on a held-out set to check for generalization.
"Although we went very quickly through the first step and the second step, these are actually the hardest part of the problem. Like in reality, as every data scientist knows, getting your data is the hardest thing."
The Counterintuitive Seed Prompt
One of the more surprising findings Mahmoud shared: the seed prompt that excluded the agent's policy outperformed the one that included it. His hypothesis is that including the full policy from the start traps the optimizer in a local minimum. Starting naive -- "if I don't have any rules, it should say everything is all right" -- with good annotations lets the algorithm explore the prompt space more effectively.
This inverts the common intuition that more information in the starting prompt is always better. In optimization terms, a good starting point isn't necessarily one that's close to the answer -- it's one that gives the optimizer room to move.
Results on a Real Benchmark
Mabrouk tested this on TauBench, a benchmark by Sierra containing 599 conversation traces from a simulated airline support agent. He split the data into 480 training and 112 validation traces, with roughly 62% compliant and 38% non-compliant conversations.
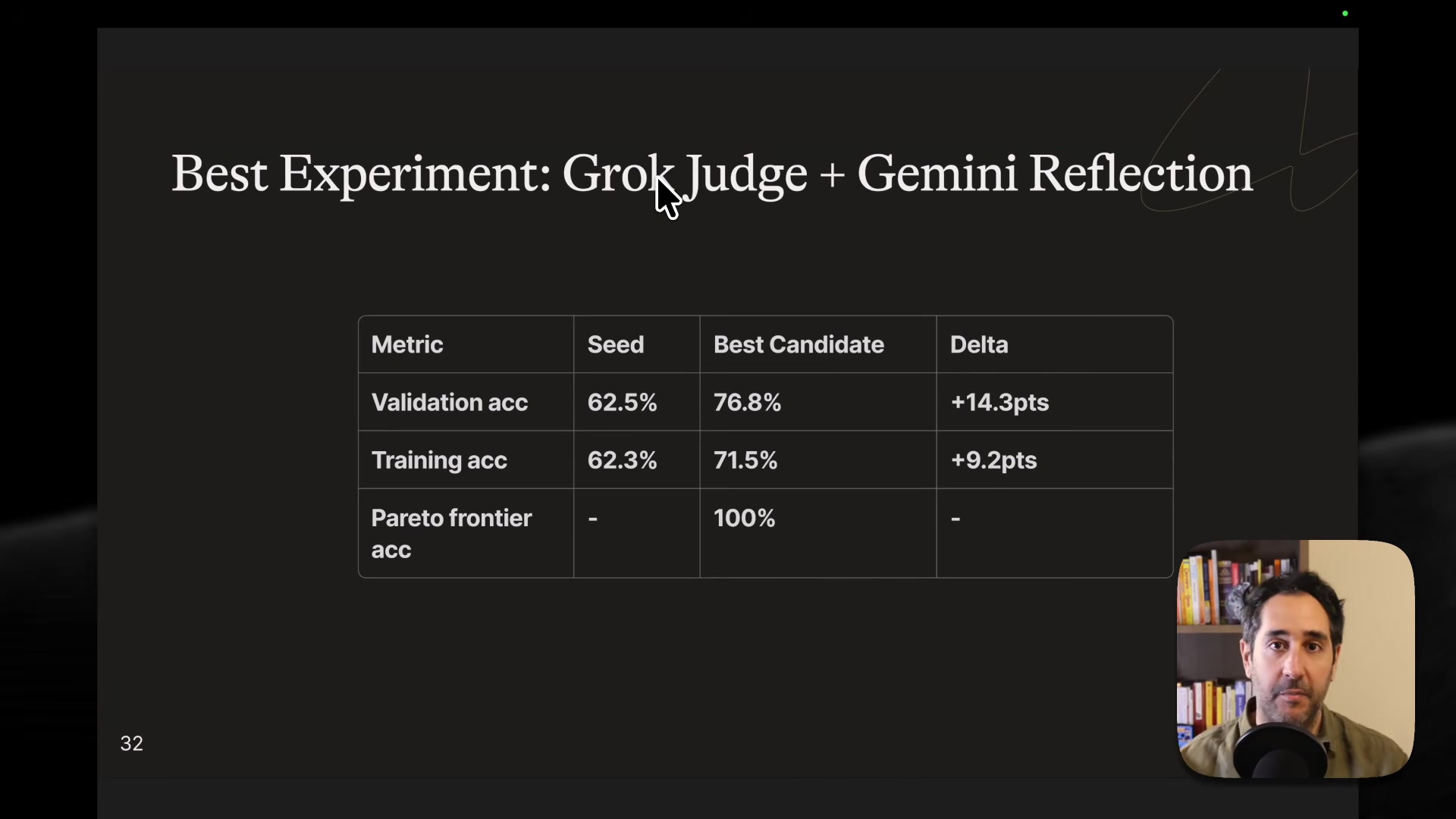
The naive seed judge scored 61% accuracy on validation, according to Mabrouk, with a 98% bias toward predicting "compliant" -- meaning it was essentially rubber-stamping everything. After GEPA optimization, he reports accuracy rose to 74% on the validation set, with the compliant prediction rate dropping to 64%, much closer to the actual distribution.
The optimized rubric had learned parts of the airline policy on its own -- cancellation rules, flight modification procedures, communication requirements -- all discovered through the optimization process rather than hand-written.
Practical Lessons from the Optimization Loop
Mahmoud shared several hard-won lessons from iterating on this approach:
- Smaller or older models failed as both judge and reflector for this complexity level. His best results came from mixing models -- Gemini for reflection, Grok for the judge -- though GPT-4.1 Mini for both also worked.
- He wrote a custom reflection template rather than using the default, embedding domain-specific priors about how to discover policy rules.
- Start with small iterations, visualize the generated candidates and reasoning, and overfit to training data first before scaling up.
- The Pareto frontier reached 100% on training data -- meaning for every training task, some candidate prompt solved it -- but consolidating all that knowledge into a single merged prompt remained the bottleneck.
"It's not an algorithm that you just take and it works from day one, unless for kind of toy examples."
Treat It Like ML, Not Prompt Engineering
Mabrouk's takeaway is straightforward: stop treating LLM evaluation as a prompt writing exercise and start treating it as a machine learning problem. Get labeled data from domain experts, optimize your evaluator systematically, and validate on held-out examples. According to his experiments, the optimization runs cost a few hundred dollars in tokens and take about an hour -- a modest investment for evaluators you can actually trust.
Mahmoud Mabrouk spoke at AI Engineer Europe 2026. Co-founder and CEO at Agenta AI.