
Your Multi-Agent System Isn't Failing Because of the AI
Sandipan Bhaumik (LinkedIn), Data & AI Tech Lead at Databricks, opened with an anecdote that set the tone for the whole talk. A single credit-scoring agent ran for two weeks in production without issues. The team added four more agents. Within days, 20% of risk ratings were wrong -- not because the LLM was hallucinating, but because a caching layer between agents wasn't invalidating correctly. A classic distributed systems race condition on stale data.
"They think adding more agents is just like adding more features. It's not. It's building a distributed system."
His argument: when multi-agent systems break, teams blame the model or the prompts. Almost every time, Bhaumik says, it's the architecture.
The Coordination Complexity Problem
Sandipan points out that going from one agent to five doesn't create five times the complexity. Five agents have at least ten potential coordination points -- each one a failure surface. The math is straightforward (pairwise connections), but teams consistently underestimate it because adding an agent feels like adding a feature.
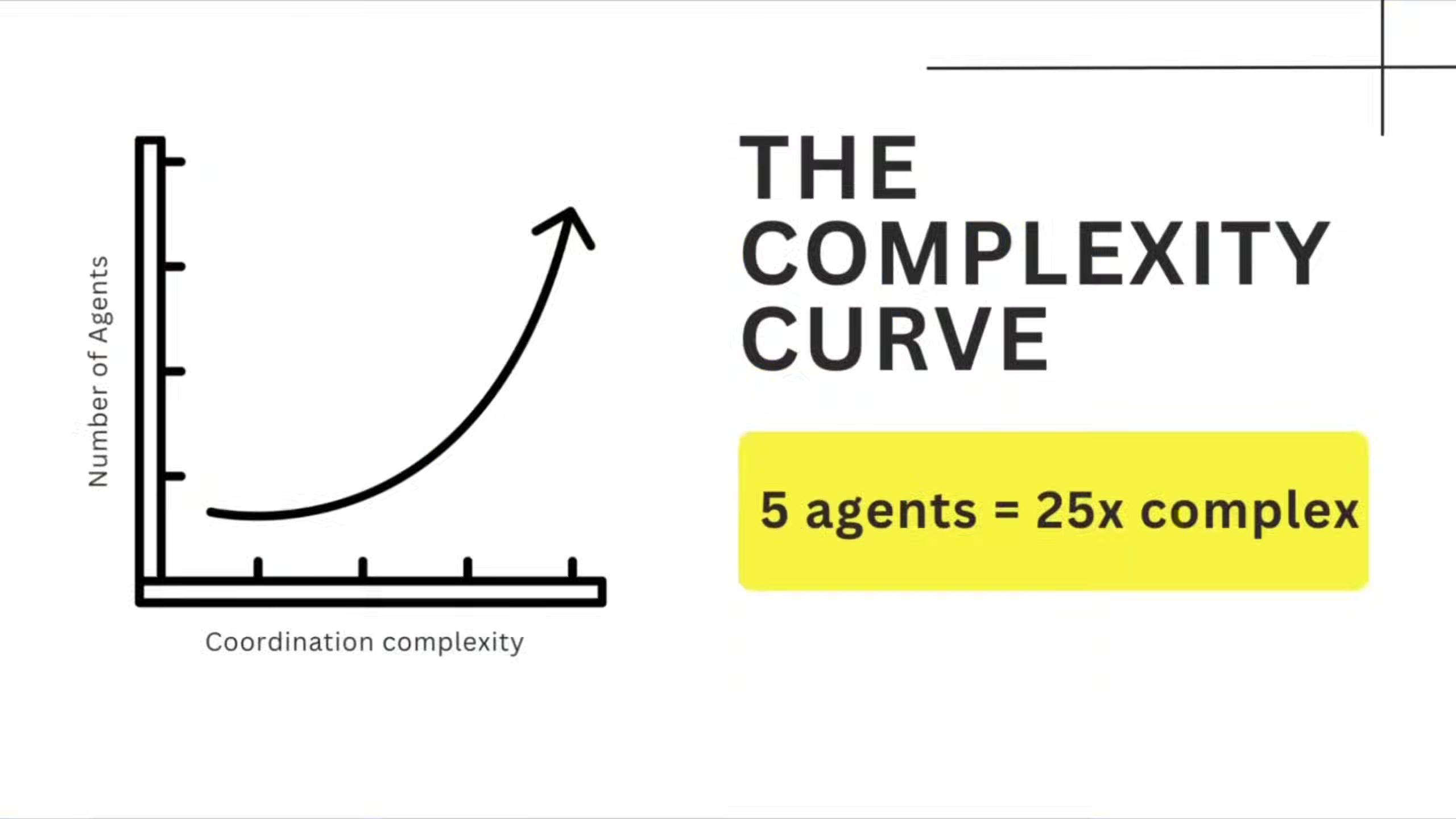
The fix, he argues, isn't better AI. It's applying decades of distributed systems engineering to a problem space that's pretending those lessons don't exist.
"This is no longer an AI problem. This is a distributed system problem."
Choreography vs. Orchestration
Sandipan breaks agent coordination into two patterns, and argues most teams pick one instinctively and regret it.
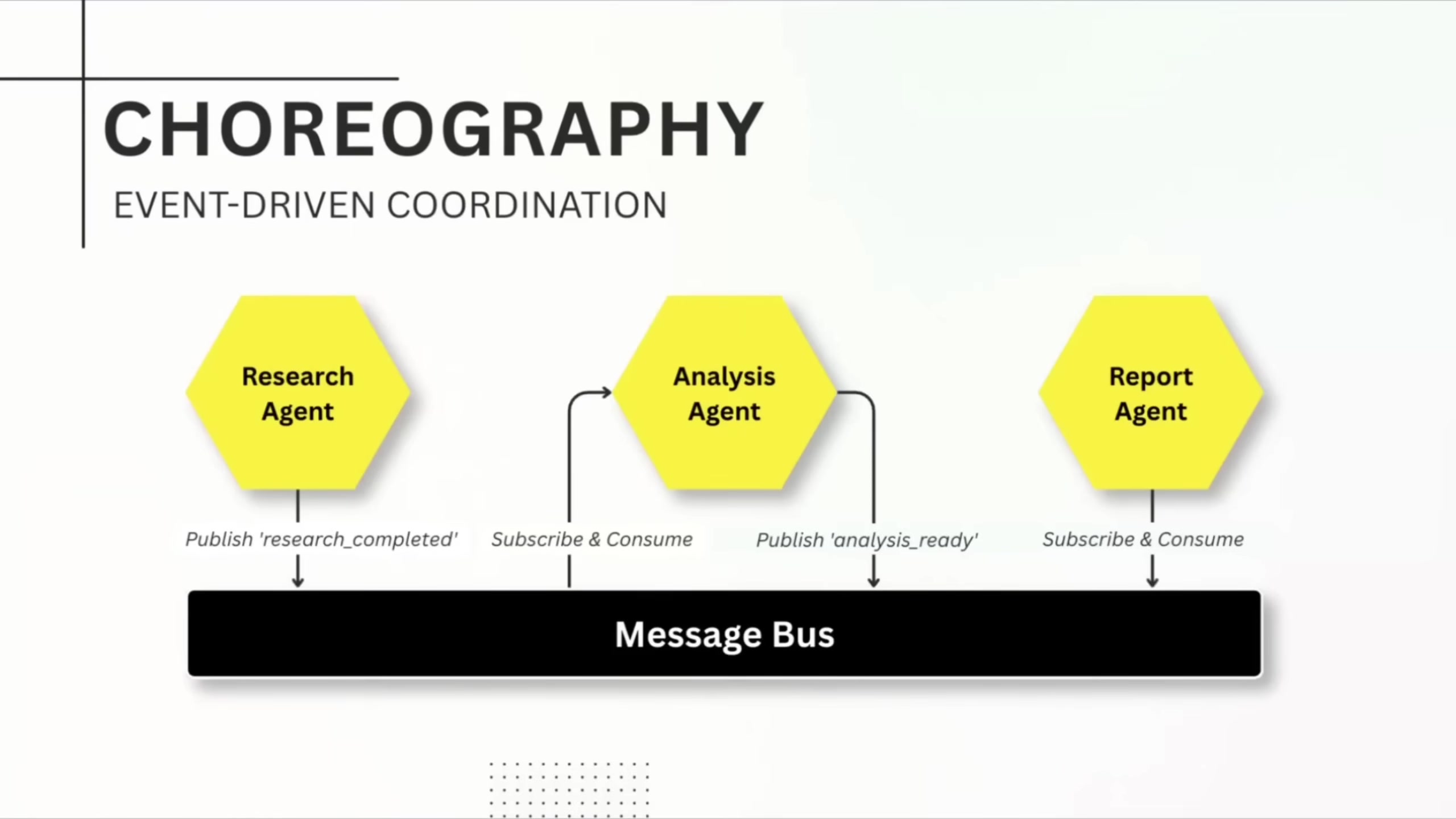
Choreography is event-driven and decentralized. Agents publish events to a message bus when they finish work; downstream agents subscribe to the event types they care about. It scales well and makes adding new agents easy. The downside: debugging is brutal without strong observability. You can't trace which agent failed to publish, whether events were consumed, or whether they were consumed twice.
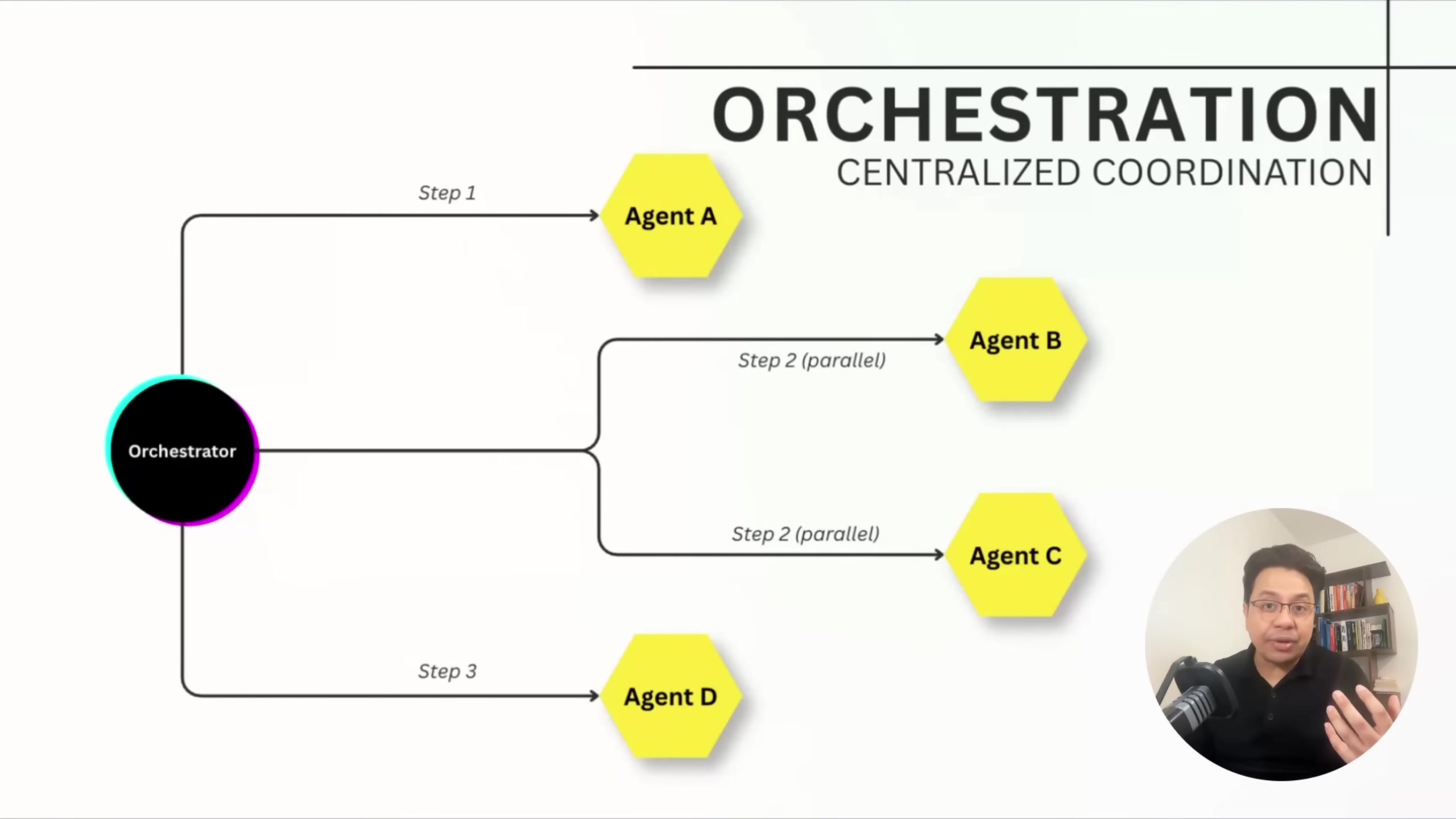
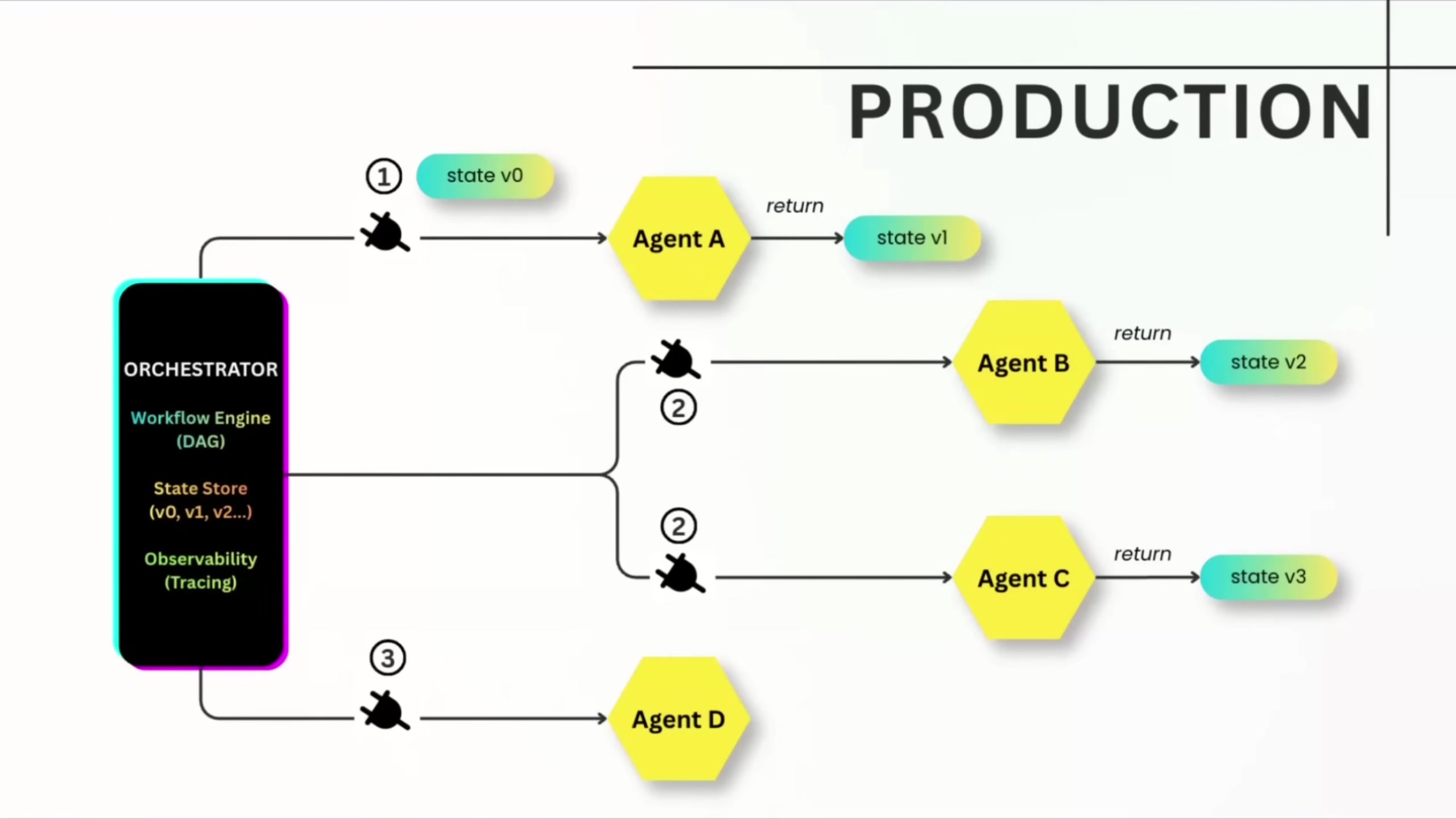
Orchestration is centralized. A workflow orchestrator calls each agent directly, manages parallelism, tracks the full execution graph, handles retries, and logs every step. Agents are deliberately simple -- they take input, do work, return output. He says financial services uses orchestration almost exclusively because rollback capability and auditability matter more than agent autonomy.
His decision framework maps workflow complexity against autonomy requirements across four quadrants.
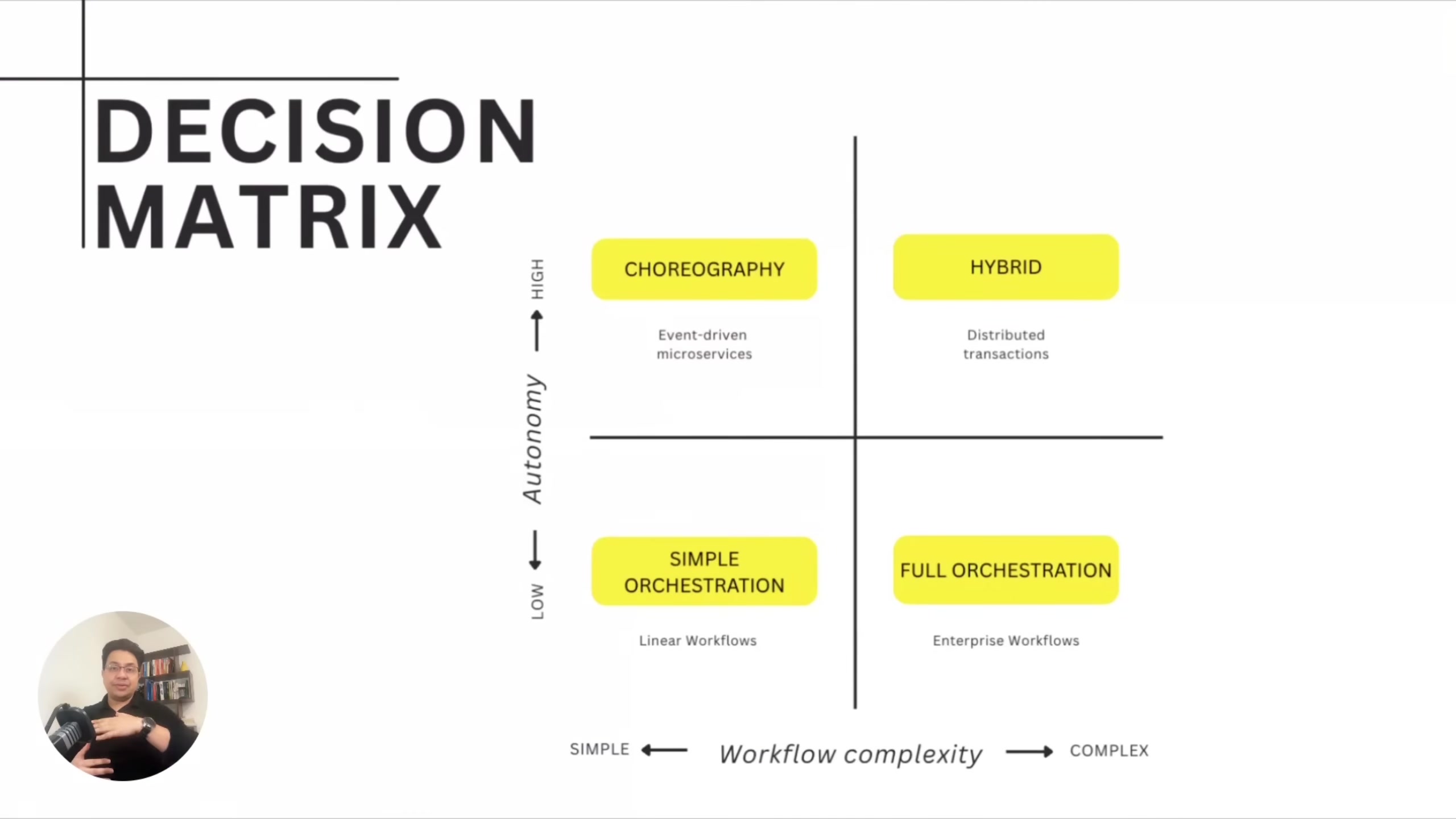
Simple workflow with high autonomy needs points to choreography. Complex workflow with low autonomy tolerance points to orchestration. Complex workflow with high autonomy needs points to hybrid patterns -- choreography with saga patterns for compensation.
"I've seen teams choose choreography because it feels more agentic, more autonomous. Then they spend months firefighting because they can't debug distributed event flows."
Immutable State Over Shared Mutable State
The anti-pattern Sandipan flags most often: shared mutable state where multiple agents read and write the same database records concurrently. Even with modern database protections, teams use default isolation levels, skip explicit locks, and ship race conditions to production.
His recommended pattern is immutable state snapshots with versioning. Each agent produces a sealed, immutable state version -- append-only inserts, never updates. At each handoff, the receiving agent validates the schema against a data contract before processing. If an agent fails, you roll back to the previous version. For debugging, you replay state evolution from version 1 through version N.
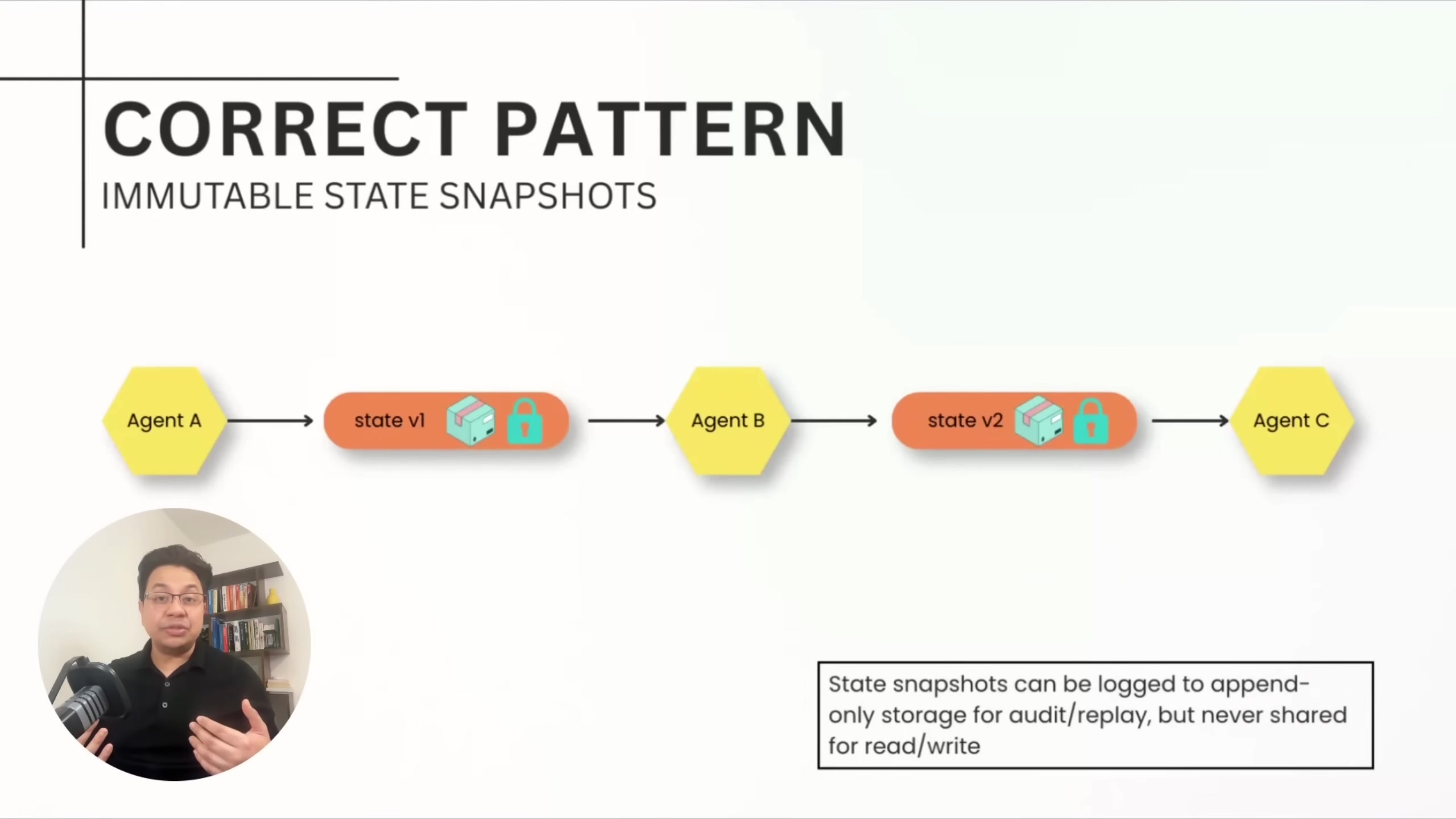
Data contracts enforce that one agent's output schema matches the next agent's expected input. If a research agent outputs data with a confidence score below a threshold, the contract rejects the handoff at the boundary rather than letting bad data propagate three agents downstream.
Circuit Breakers and Compensation
He covers two failure recovery patterns he considers essential for production multi-agent systems.
Circuit breakers wrap every agent call. After a configurable number of consecutive failures, the circuit opens and the system fails fast instead of waiting for timeouts. After a cooldown period, it goes half-open and tests with a single request. This prevents one failing agent from cascading into a full system outage.
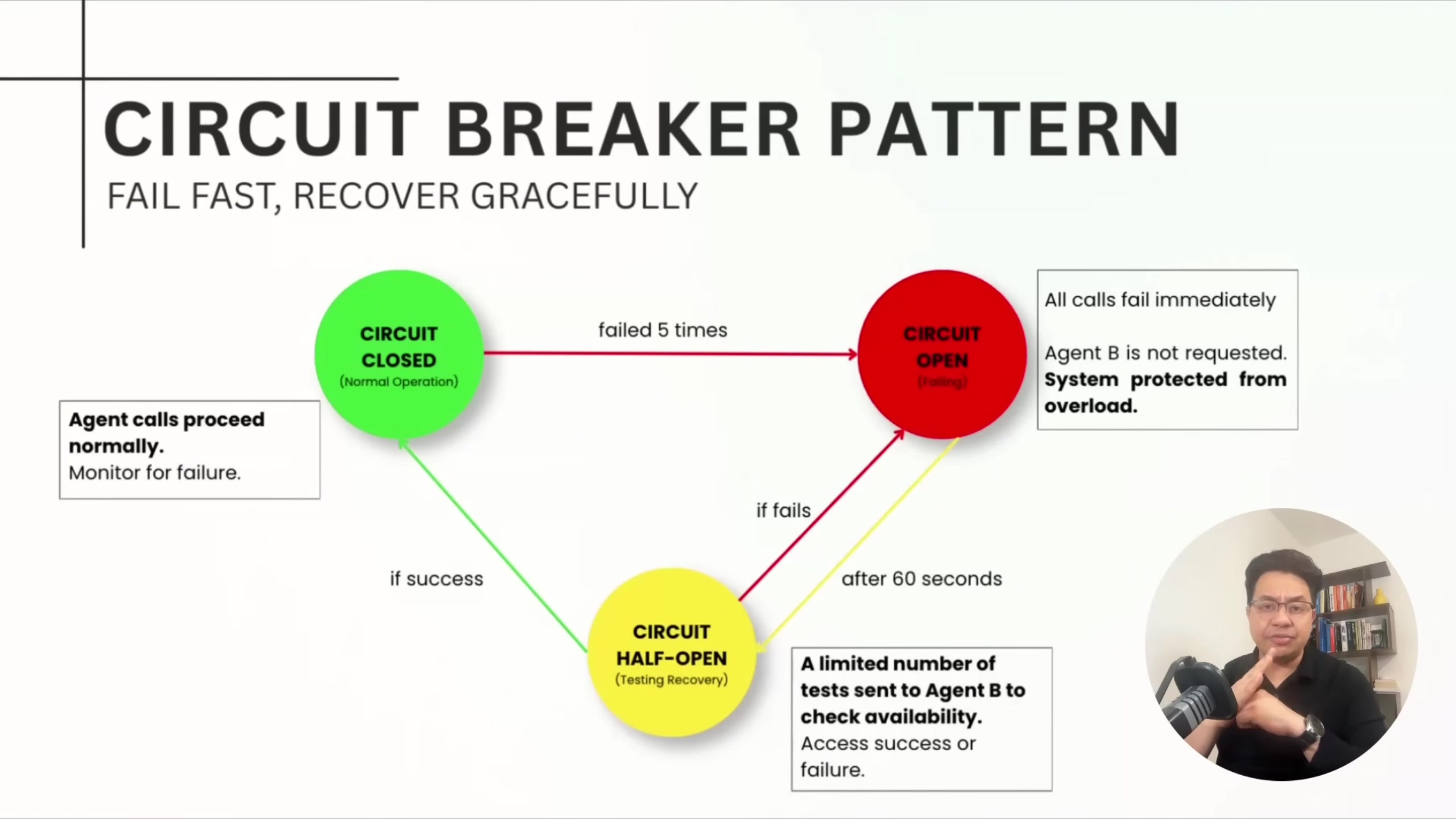
"Circuit breakers are the single most important failure recovery pattern for multi-agent systems."
The saga/compensation pattern gives transactional semantics across distributed agents. Every agent implements two methods: execute and compensate. If an agent fails mid-workflow, the orchestrator walks backward through previously successful agents, calling compensate on each to undo their work.
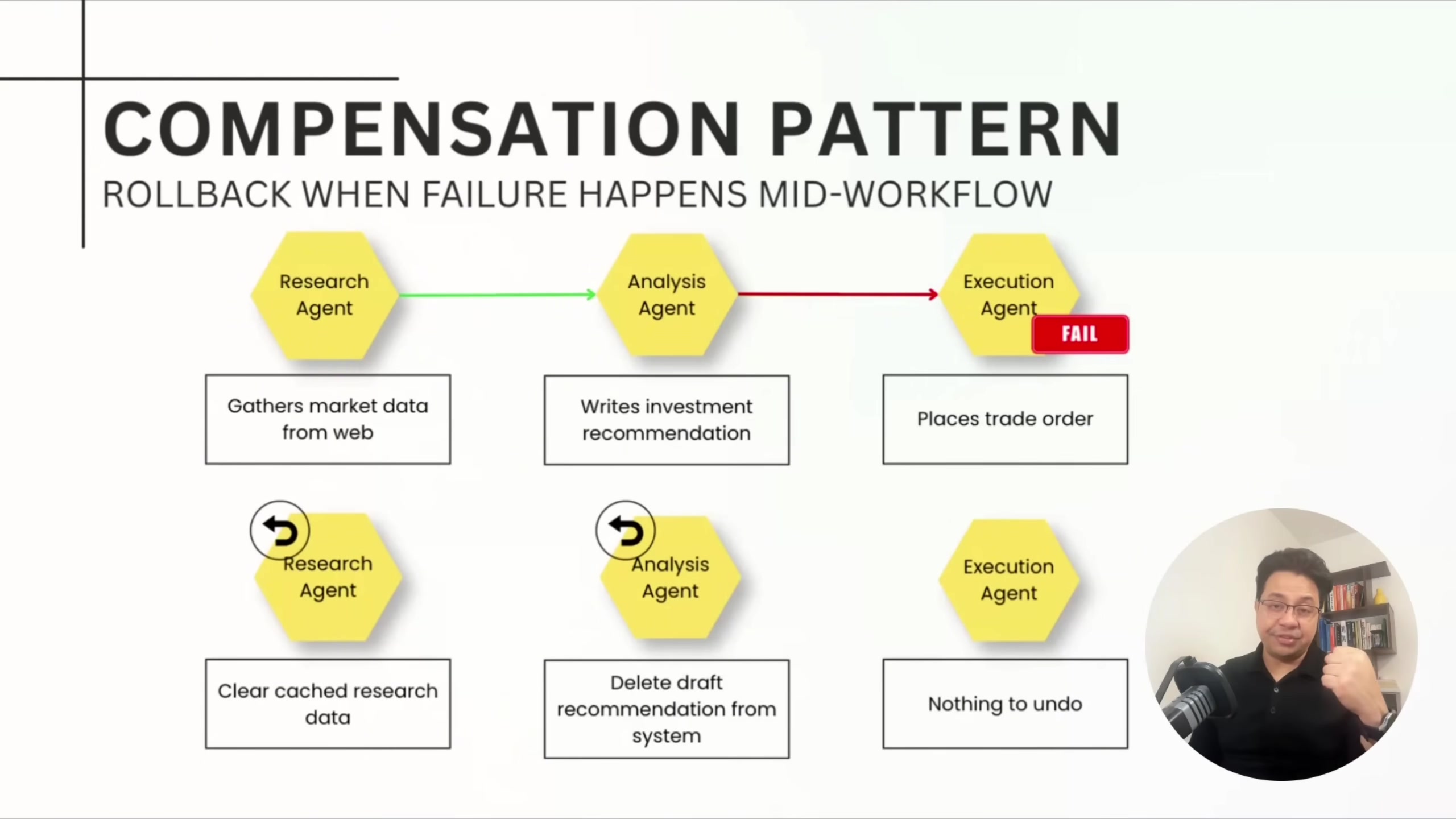
Sandipan acknowledges it's not glamorous work. But it's how production systems handle partial failures without human intervention at 2 a.m.
The Unsexy Work That Keeps Systems Running
Bhaumik's closing is blunt. Demos are easy -- anyone can use an LLM to show something cool. The hard part is everything he covered: choreography versus orchestration decisions, immutable state, circuit breakers. All of it is infrastructure work that won't get applause.
"You won't get applause for implementing a circuit breaker, but you make your systems more reliable. They don't fail at 2 a.m. in the night."
His core argument is that the teams succeeding with multi-agent systems in production aren't the ones with the best prompts or the most capable models. They're the ones treating agent coordination as what it is -- a distributed systems problem -- and applying the patterns that have solved those problems for decades.
Sandipan Bhaumik spoke at AI Engineer Europe 2026. Data & AI Tech Lead at Databricks.