
Your AI Agent Is a Junior Developer. Manage It Like One.
Brendan O'Leary (LinkedIn, X), a Developer Relations Engineer at Kilo Code, opened his AI Engineer Europe talk with a observation that's easy to nod along with and hard to act on: most engineers have used AI tools by now, but almost none of them can articulate how they actually work with them. What do they hand off? What do they keep? How do they decide? That gap -- between using AI and working with it -- is where O'Leary spent his 27 minutes.
"Tools are things that you pick up and put down. You use a hammer. You don't work with a hammer."
The Junior Developer Mental Model
O'Leary's central framing is blunt and practical:
"You kind of have to think about your AI agent as an energetic, enthusiastic, extremely well-read, often confidently wrong junior developer."
This isn't just a throwaway analogy. He uses it as an actual management framework. The skills that make someone a good engineering manager of junior developers -- giving clear context, scoping work tightly, reviewing output carefully -- are exactly the skills that transfer to working with coding agents. If you've ever handed a vague ticket to an intern and gotten back something technically functional but completely wrong-headed, you already understand the failure mode.

Context Is the Bottleneck
The bulk of Brendan's technical content centers on what he calls context engineering -- the idea that the quality of an agent's output is bounded by the quality of context you give it. He claims context quality starts to degrade once the context window is roughly half full, and that stale or irrelevant context can actively poison output.
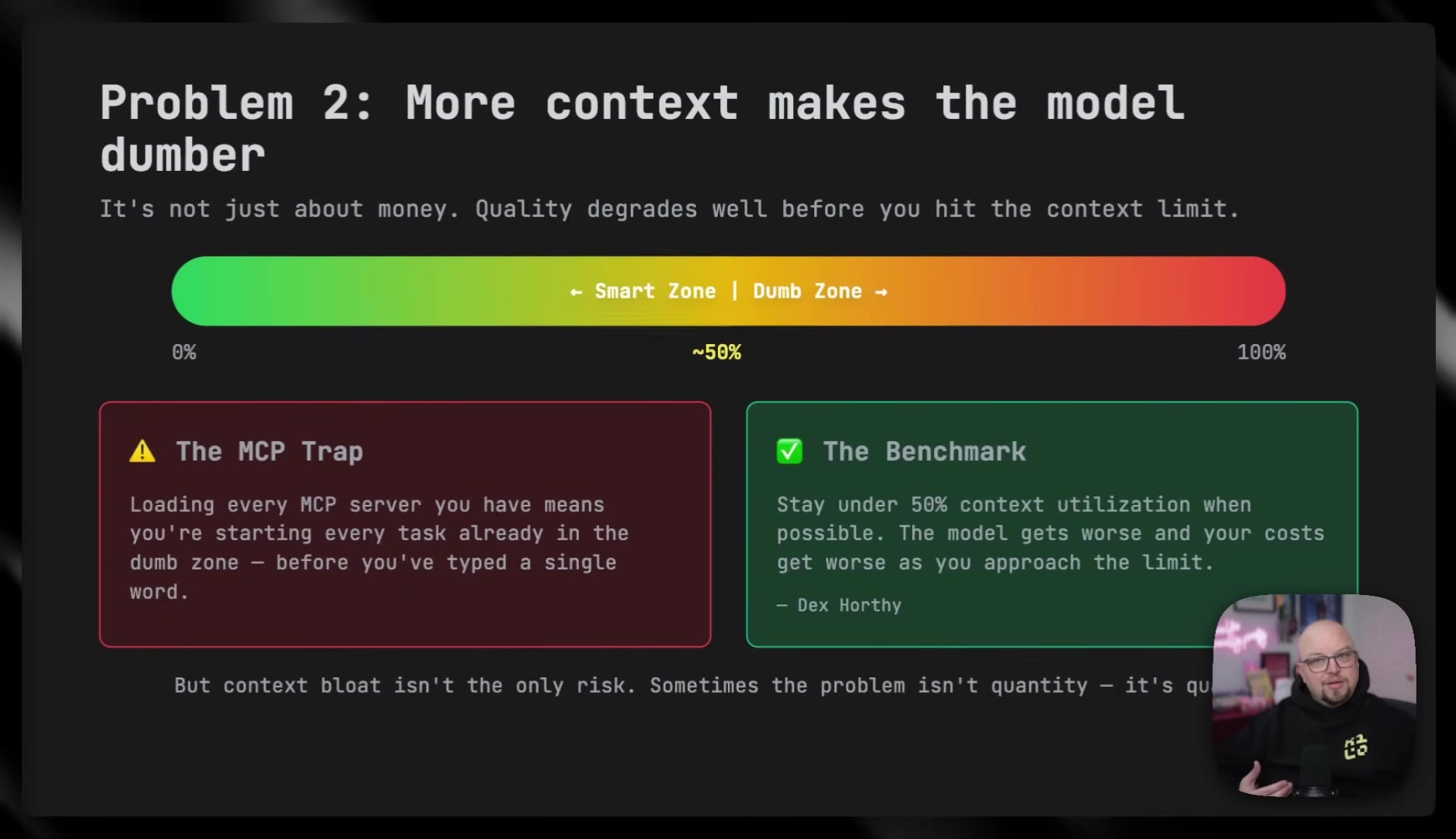
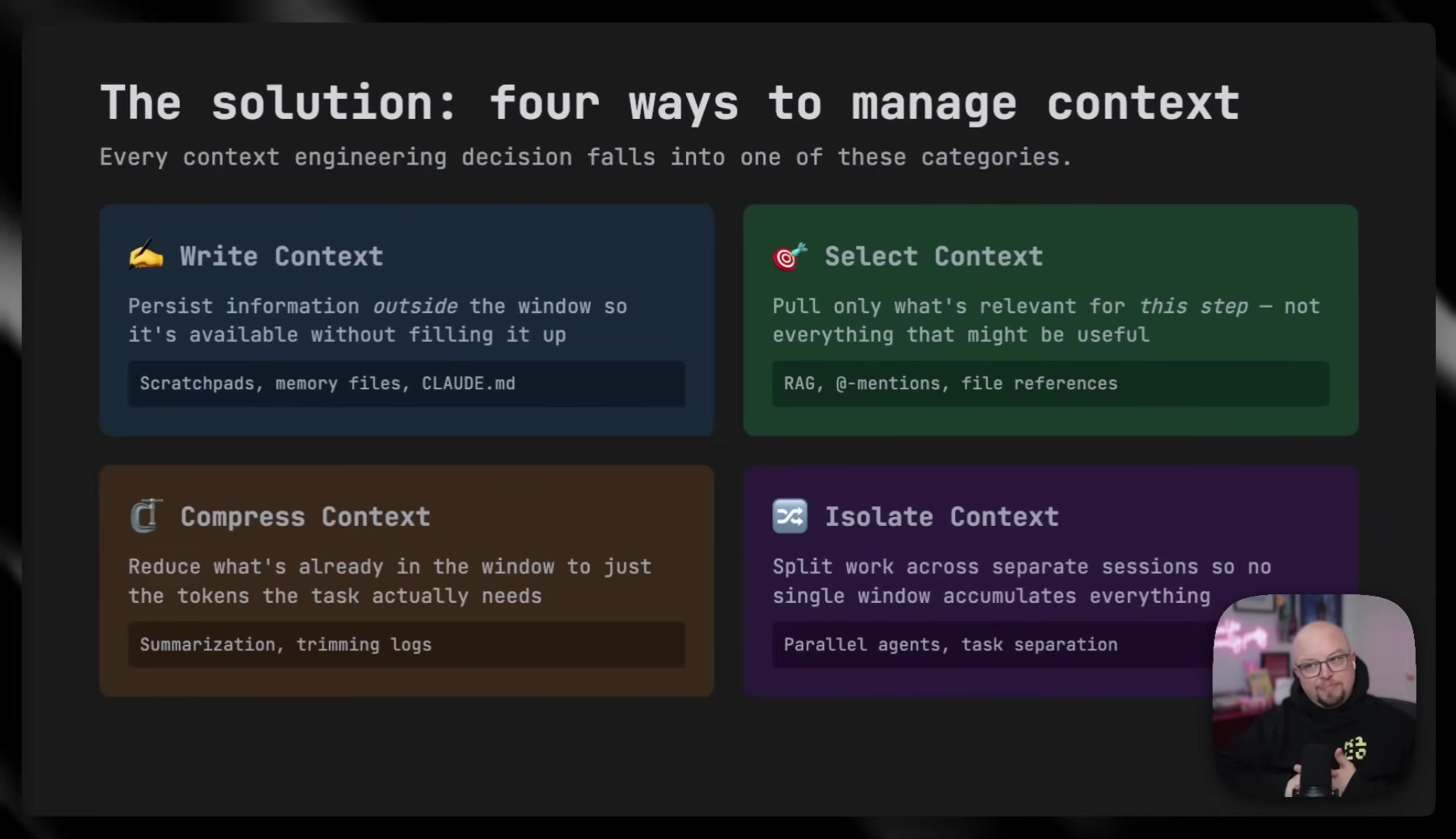
His four practices for managing context:
- Persist information outside the context window -- scratch pads, memory files, and project-level instruction files so the agent can access knowledge without bloating the live session.
- Be selective -- only pull in what's relevant for the current step. He specifically warns against leaving unnecessary tool integrations enabled, since each one adds tokens to the system prompt on every interaction.
- Summarize and compress -- after a long debugging session, distill the context down to just the problem and solution before moving to implementation.
- Isolate -- split work across parallel agents or sessions to prevent context accumulation. He points to the rise of parallel agent workflows over the past several months as a direct response to this problem.
The selectivity point lands hard. O'Leary describes a scenario where a database integration tool is left enabled during frontend work -- it wastes tokens and can mislead the agent into touching things it shouldn't. The principle is the same one that applies to human developers: don't leave irrelevant tools and docs scattered across someone's desk and expect focused work.
Research First, Code Last
O'Leary's recommended workflow inverts the assumption that AI's value is in code generation speed. He argues the real leverage comes before any code gets written.
He quotes Dex Horthy: "A bad line of research can potentially be hundreds of lines of bad code."
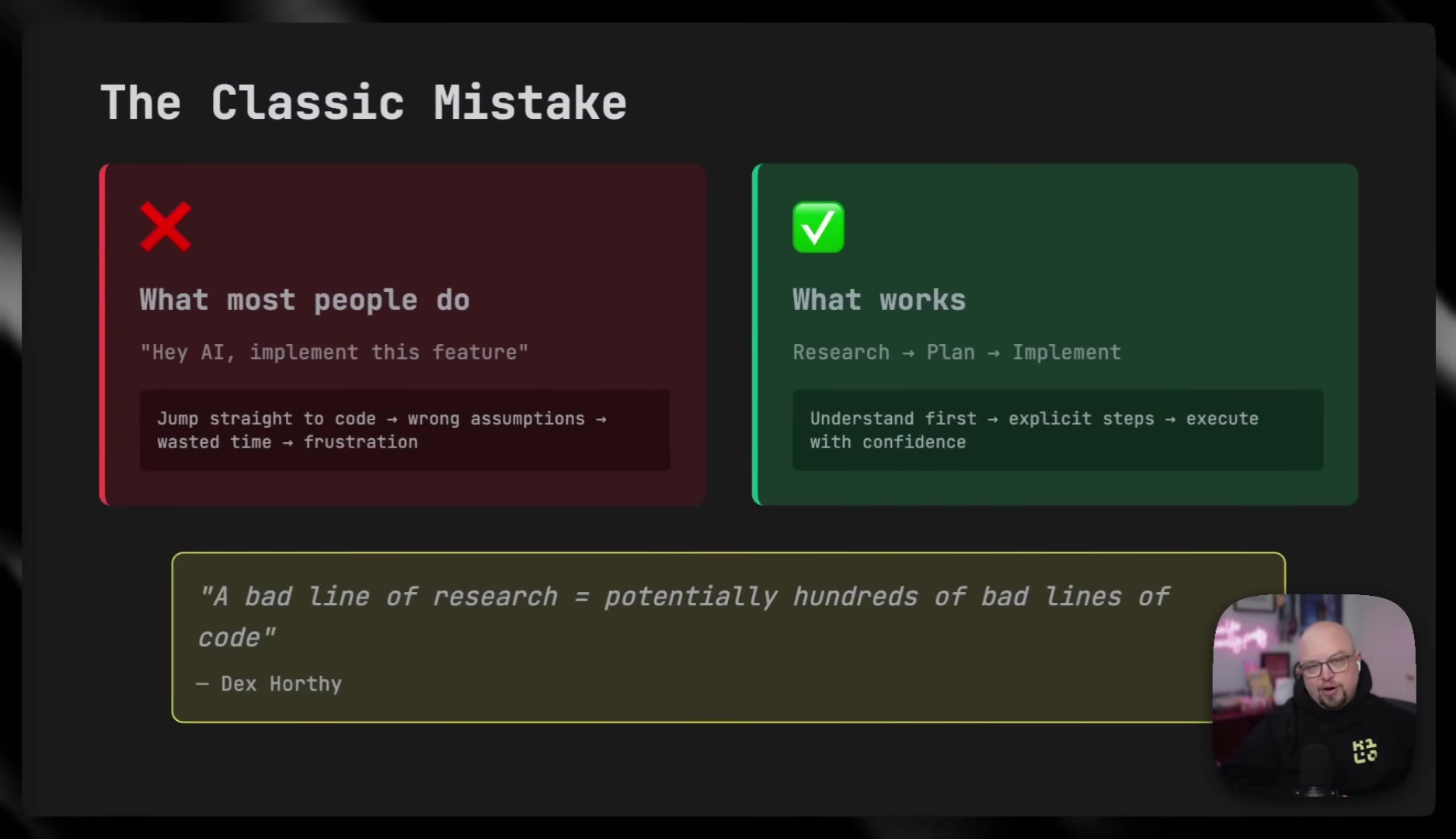
The workflow breaks into three phases:
- Research: Use a restricted mode where the agent can read files and discuss but cannot write code. The goal is to understand the system, identify relevant files, map data flow, and brainstorm edge cases. The output is a research document the engineer reviews.
- Plan: Outline specific files to create or change, define verification steps and test strategies, explicitly scope what's in and out. The output is a plan file with step-by-step instructions.
- Implement: Start a fresh session with only the plan as context. This keeps context lean, enables careful per-change review, and -- because the hard thinking is already done -- can even use smaller, cheaper models.
The fresh-session trick is worth highlighting. By discarding the research and planning context and starting implementation with just the plan document, you sidestep the context degradation problem entirely. The plan becomes the distillation -- all the thinking, none of the noise.
Configuring Agent Behavior
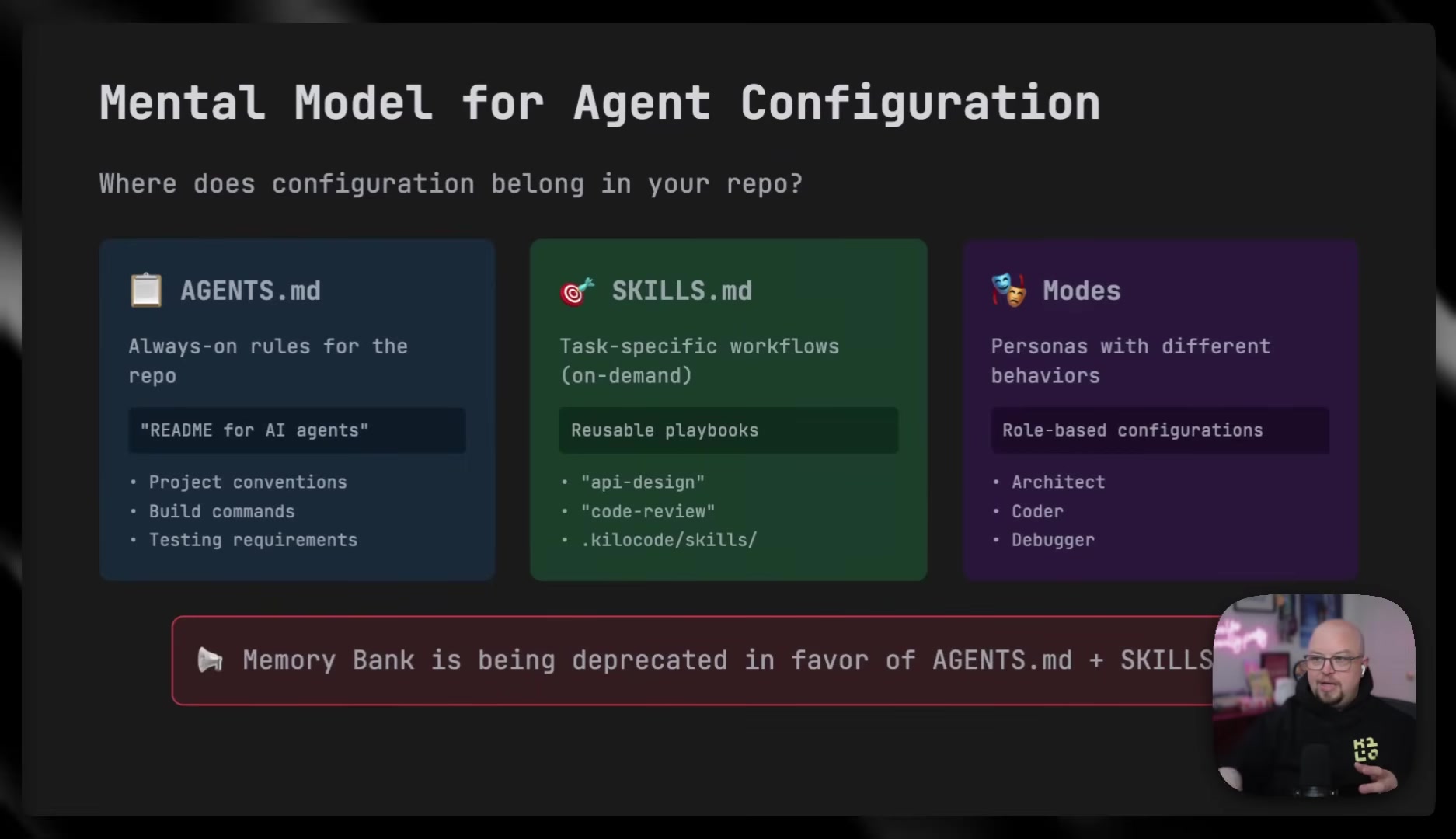
Brendan breaks agent configuration into three layers:
- Modes -- role-based behavioral configurations that constrain what the agent can do (research-only, planning, coding).
- Project-level instruction files -- always-on rules covering conventions, build commands, and pre-commit requirements. O'Leary describes these as becoming a "de facto standard" across tools.
- Skills -- on-demand reusable playbooks for specific workflows, like generating changelogs or creating assets from templates.
He also touches on connecting agents to internal APIs, listing four approaches for enterprises: use existing OpenAPI specs, convert API docs to markdown stored in the repo, provide a reference URL the agent pulls fresh each time, or build a custom integration server for complex multi-system workflows.
Thinking Is the Job
O'Leary's talk keeps circling back to one idea: the agent amplifies whatever you bring to it. Good preparation produces good code. Sloppy preparation produces confident-sounding garbage.
He quotes Dex Horthy again to make the point stick:
"AI can't replace thinking. It can only amplify the thinking you've done or the lack of thinking you haven't done."
The actionable takeaway from Brendan's talk is that the highest-leverage skill for working with coding agents isn't prompt engineering or tool configuration -- it's the unglamorous work of researching a problem thoroughly, writing a clear plan, and scoping the implementation tightly before letting the agent touch a single line of code. The same things that make code reviews go smoothly with human developers make agent output worth keeping.
Brendan O'Leary spoke at AI Engineer Europe 2026. Developer Relations Engineer at Kilo Code.