
The Cure for the Vibe Coding Hangover
A practical framework for building software with AI agents.
This was ultimately presented as a talk at the AI Engineer Code Summit in November 2025.
Inspiration strikes. You've got an idea, and you know exactly how you're going to build it: let's vibe code, baby! You fire up your favorite AI coding agent, you jam in those prompts, and you hand it over. The app works. This is what 10x engineering really feels like. You're a genius -- a rebel in the AI revolution.
Then Monday rolls around. You want to add a feature, or change the way something works, and you realize that you don't understand it, you can't maintain it, and you have to throw most or all of it away.

That's the hangover. Vibe coding is the low-spec, zero-planning approach to AI-accelerated development that feels productive but results in brittle, unmaintainable demo-ware. The hangover is the despair that follows when you try to build maintainable, understandable software that way.
There's a cure, though, and it's a framework for building with AI coding agents. That's what this is about.
Vibe coding feels like 10x engineering right up until the moment you have to live with what it built.
Who This Is For
You'll dig this if you value programming as a daily learning experience. If you want to understand and own the software you write with AI coding agents, just as you own all the other software you write. If you want to be the boss of the coding agents, not their confused intern. If working with agents lately makes you feel like a prompt jockey and no longer an AI engineer. If you're sick of throwing away code, burning time and tokens. Or if you want to use coding agents to build production applications that do real work.
On the other hand ...

This isn't for you if programming is a job and not a craft you're refining -- and that works for you. If you're satisfied having AI just do it for you without needing to understand how or why. Or if vibe coding gets you what you need and that's good enough. None of that is a judgment. It's just a very different path than the one I'm taking here.
The Framework in Overview
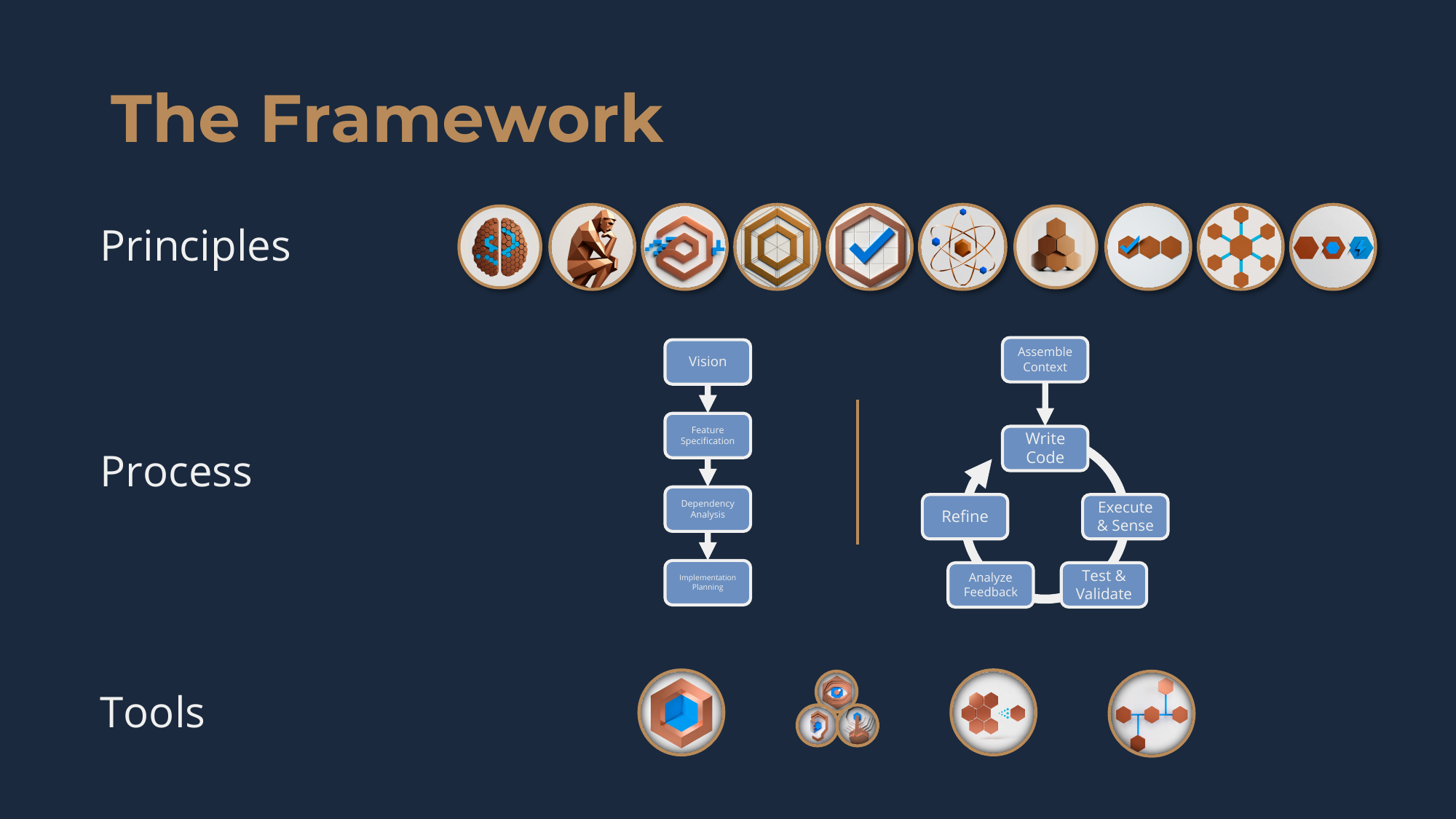
The Framework has three pillars.
- Principles are the philosophy underpinning all of it.
- Process is the workflow for actually getting software built using AI.
- Tools are the accelerators and enablers of the process -- which also reflect the principles.
So what can you build with it? Really, anything. The Framework is adaptive to all types of software.

Here are a few examples of working software in the wild right now, built with this approach:
- specialized litigation support applications for law firms;
- real-time appliance monitoring packages for smart cooking devices;
- digital publishing systems for dynamic content replatforming;
- a code execution environment for secure, isolated development workflows;
- a context-management suite that preserves conversational data across AI sessions;
- a digital media production system for studios
... and on and on. Plus a litany of smaller tools and utilities used daily to automate routine tasks.
The point is that these aren't toys. They're real software applications that do real work every day, and they're evolved and maintained at breakneck pace by AI engineers who apply this Framework.
The Principles

There are ten principles. They map across three groups:
- general principles that apply overarchingly,
- principles that skew toward the planning phase, and
- principles that skew toward implementation.
For each one, it helps to understand the problem it came from, the idea that answers it, and the one line I use to remember it.
1. AI Engineering Is Accelerated Learning

The problem this came from: treating AI coding agents as pure productivity tools, just to crank out code faster. Using AI to generate software and learning nothing from the process. Six months later, being no better an engineer -- plateaued. Or worse, becoming dependent on AI for debugging, modifications, architectural decisions. That's not AI augmentation. That's AI dependency.
The Framework isn't just about building faster -- it's a learning system. Every step creates specific learning opportunities, so you're not just shipping software, you're building yourself. The software is valuable, but the engineer you become is exponentially more valuable.
Always. Be. Learning. A-always, B-be, L-learning.

2. You Are the Architect, the Agent Is the Implementer

The problem: treating AI agents as replacements for architectural thinking, rather than implementers of your decisions once those decisions are well-specified.
Keep the architect/implementer boundary crystal clear. You own the thinking -- architecture and interfaces, the intent of the system, its structure, the design decisions and their trade-offs. The agent handles the doing -- implementation, typing code, following patterns, implementing the tests you specify, banging out boilerplate.
Delegate the doing, not the thinking.
3. Slow Down and Iterate to Go Fast

It's a little counterintuitive. The problem is the starting-over cycle: without deliberate iteration on validated work, you repeatedly start from scratch. Three months in, you've got multiple abandoned attempts instead of one consistently improving system.
Deliberate iteration enables compounding returns on both understanding and productivity. Week one feels slow. Week two builds momentum. Week three is dramatically faster.
Compound progress, accelerate velocity.
4. Specification > Prompt Engineering

The problem: prompt engineering treats AI interaction as an optimization problem rather than a communication problem -- hunting for magic words that produce the right output, instead of clearly defining what "right" means.
Specifications are different from prompts. A specification is a structured, precise definition of requirements, behavior, interfaces, and acceptance criteria. Writing one forces architectural thinking: you have to understand the problem completely, define interfaces precisely, and anticipate edge cases. In turn, the specification gives the agent clear, unambiguous direction -- it implements what you specified, not what it interpreted from a conversational prompt.
Write the blueprint, not the prompt.
5. Define "Done" Before Implementing

The problem: starting implementation without executable tests and observable success criteria means the agent has no clear completion criteria and no immediate feedback. It can't self-validate, can't self-correct, and doesn't know when it's done -- at least not in a way consistent with your specifications.
Defining "done" up front keeps you thinking deeply about requirements, and it lets the agent work autonomously. Tests defined upfront give the agent clear stop conditions and immediate feedback during implementation. And there's more than tests: the multi-sensory validation we'll get to lets agents observe through visual senses (what renders), auditory senses (what they hear through logs and errors), and tactile senses (how they interact with the system). Tests verify the correctness of the implementation; the senses reveal the actual behavior of the software as it's being built. A feature is done when the tests pass and the senses come back clean.
Specify success, then build.
6. Feature Atomicity

The problem: writing non-atomic features leaves the decomposition work for implementation time, which forces the agent to make architectural decisions on the fly.
Feature atomicity forces you to completely decompose each feature during specification, which then lets the agent implement within a manageable scope. Features become implementation work units -- atomic, irreducible tasks ready for an agent to execute completely. Keep them as small as possible to make agent implementation as successful as possible.
Reduce until irreducible.
7. Dependency-Driven Development

The problem: implementing without explicit dependency analysis treats all features as independent, when we know they actually form an interconnected graph.
Dependency-driven development forces you to understand how features relate and integrate -- and it ensures the agent never implements a feature that depends on incomplete work.
Schedule implementation by dependencies.
8. Implement One Atomic Feature at a Time

Now the implementation-related principles. The problem: working on multiple features treats implementation as parallel streams that can be context-switched freely. But implementation quality depends on sustained focus, complete context, and very tight feedback loops. Jumping between features fragments your focus.
So the agent implements a single, atomically-defined feature. You study it and understand it. You validate that it works. You commit it as a checkpoint. Then you move to the next. That rhythm builds both momentum and deepening understanding -- working software and engineering knowledge at the same time.
Complete one, commit one, continue.
9. Context Engineering and Management

The problem: treating context as something that just happens automatically, rather than something you actively engineer. You let conversation history passively accumulate instead of curating what actually matters. And if you don't build context resilience, state eventually fails to persist and you lose continuity.
So don't rely on conversational state persisting. Capture architectural decisions in persistent documents -- specifications, plans, design documents -- and build context from those artifacts, not from yours or your agents' memory.
Curate context, don't accumulate it.
10. Make It Work, Make It Right, Make It Fast

This one is borrowed from the annals of software engineering. The problem is treating all three phases as equally important from the start, or trying to achieve them all at once.
The Framework focuses on getting to make it work -- working software you can ship and use. Only after real usage reveals what matters do you selectively invest in make it right and make it fast. So stop pursuing elegance and performance upfront. Direct the agent explicitly to make it work -- a simple, functional implementation that passes tests and ships quickly -- and let real usage reveal what deserves further investment.
Build, ship, learn, improve.

So there they are -- ten principles, the philosophy that makes The Framework work. Mind sufficiently blown? Stick with me; it gets better.
The Process
The process is where we put the principles to work -- principles in action. It has two distinct phases:
- the planning phase, where you do all the architectural thinking to define what to build, and
- the implementation phase, where the agent executes your specifications with your oversight and validation.
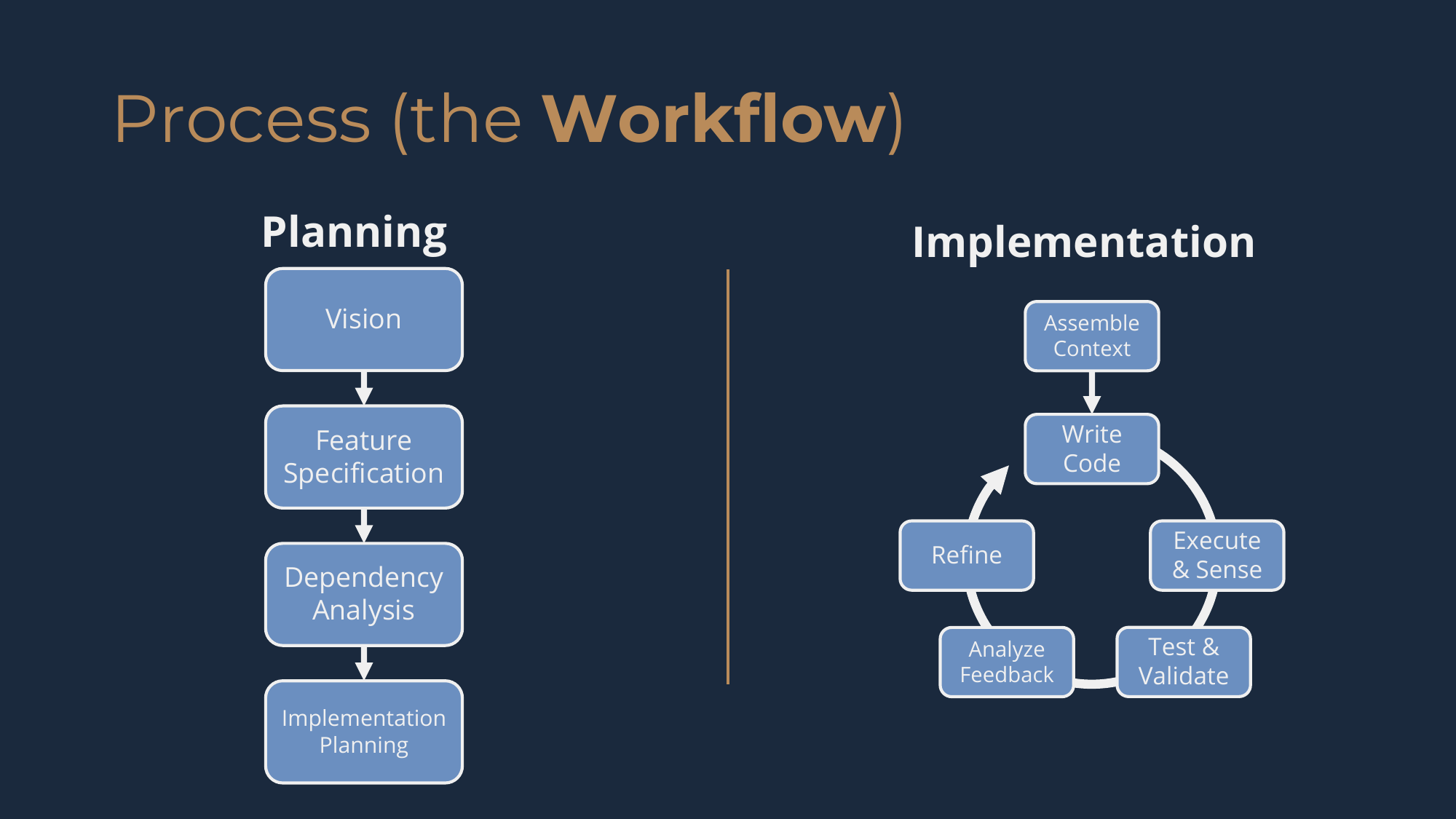
Planning produces the artifacts that enable autonomous agent implementation. Implementation then uses those artifacts to build working software, feature by feature.
The Planning Phase
Planning is where you complete your architectural thinking. You transform a vague project idea into atomic, sequenced, fully-specified features ready for implementation. This is purely your work -- the architectural decisions, the decomposition, the specification writing, the dependency analysis. The agent can assist as a thinking partner, but you make every decision.
The five planning steps are sequential and build on each other: Vision → Features → Specification → Dependencies → Plan. It's a highly iterative process of extracting and refining your thinking into tangible artifacts. The input and output of each step are a template and a completed template, respectively -- a lot of work has gone into well-structured templates that both guide the thinking and capture the results.
Planning Step 1: Vision Capture
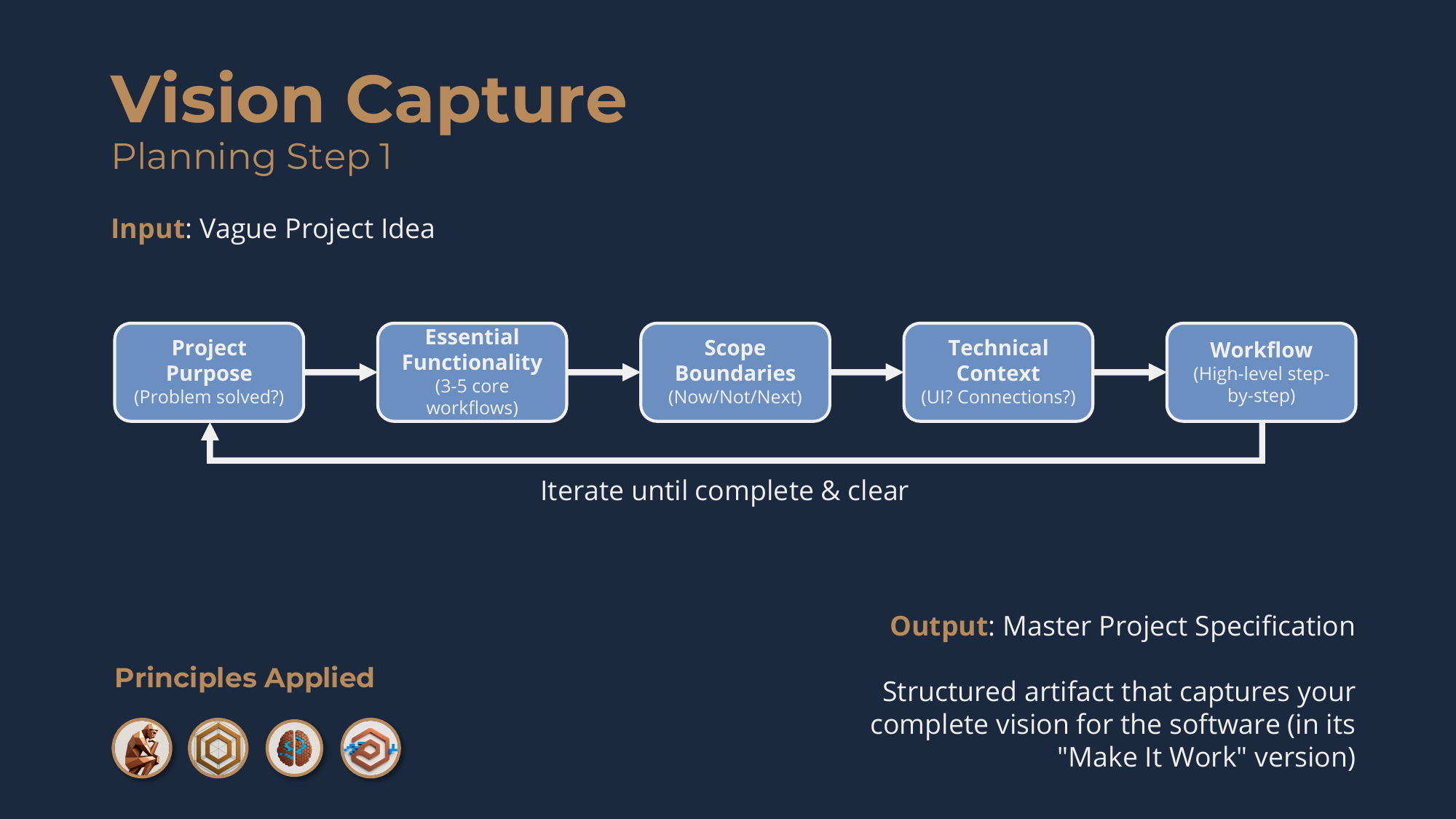
The purpose is to transform your vague project idea into a complete, structured Master Project Specification that articulates the problem, the users, the functionality, the scope, and the workflows.
The problem it solves: your initial idea exists only in your head, and it's incomplete. You have a general sense of the problem and an approach, but the details are fuzzy, the implicit assumptions are unexamined, and critical aspects are unformed. Without structured exploration you can't communicate your thinking, articulate requirements clearly, or create a shared foundation the agent can build on.
So you think out loud with an agent -- optional, but strongly recommended -- to refine and capture your vision across five sections:
- Project purpose -- the problem you're solving, who experiences it, and the core value your software delivers.
- Essential functionality -- the three to five fundamental workflows that solve the problem.
- Scope boundaries -- explicit now / not / next decisions: now (must-have for the make-it-work version), not (out of scope), next (future enhancements).
- Technical context -- where it runs, how users interact, what systems it connects to.
- Workflow details -- for each core workflow, the goal, the high-level steps, and the expected outcome.
You iterate until the vision is clear and complete. The agent is great here for surfacing gaps, suggesting edge cases, and probing assumptions -- but you make every decision. The output is the Master Project Specification, the foundation for extracting features in step two.
Planning Step 2: Feature Identification and Categorization
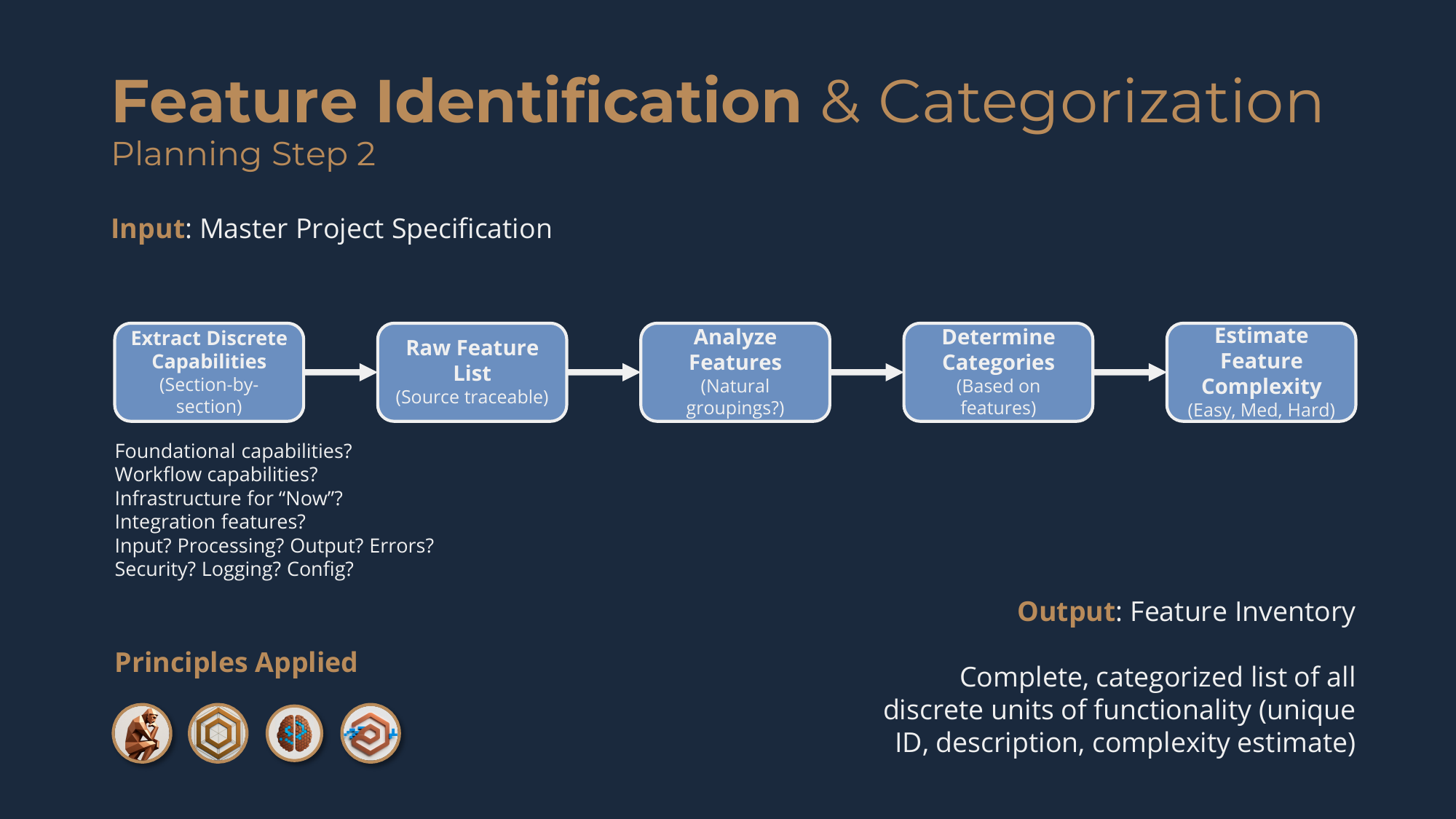
The purpose is to systematically extract every unit of functionality from your Master Project Specification and organize them into a categorized Feature Inventory.
You don't jump straight from high-level vision to detailed feature specs -- that's too big a leap. So you work through the specification section by section with targeted extraction questions: what foundational capabilities does the system need; what discrete capabilities does each workflow require; what infrastructure makes the make-it-work version work now; what platform, integration, and interface features are needed; for each workflow, what handles input, processing, output, errors, and feedback; and across everything, what security, logging, configuration, and testing features span the system. You document each feature's source for traceability.
You build the raw feature list first -- capturing every capability, not organizing yet -- and challenge completeness ("what handles errors? what validates input? what provides feedback?"). Then you analyze for natural groupings, settling on three to seven categories that reflect how your specific software is structured, assign each feature to its best-fit category with a unique ID (like CORE-001 or API-101), and give each an initial complexity estimate of easy, medium, or hard. The categories emerge from your actual features, not from a predetermined template. The output is the Feature Inventory.
Planning Step 3: Iterative Specification Development
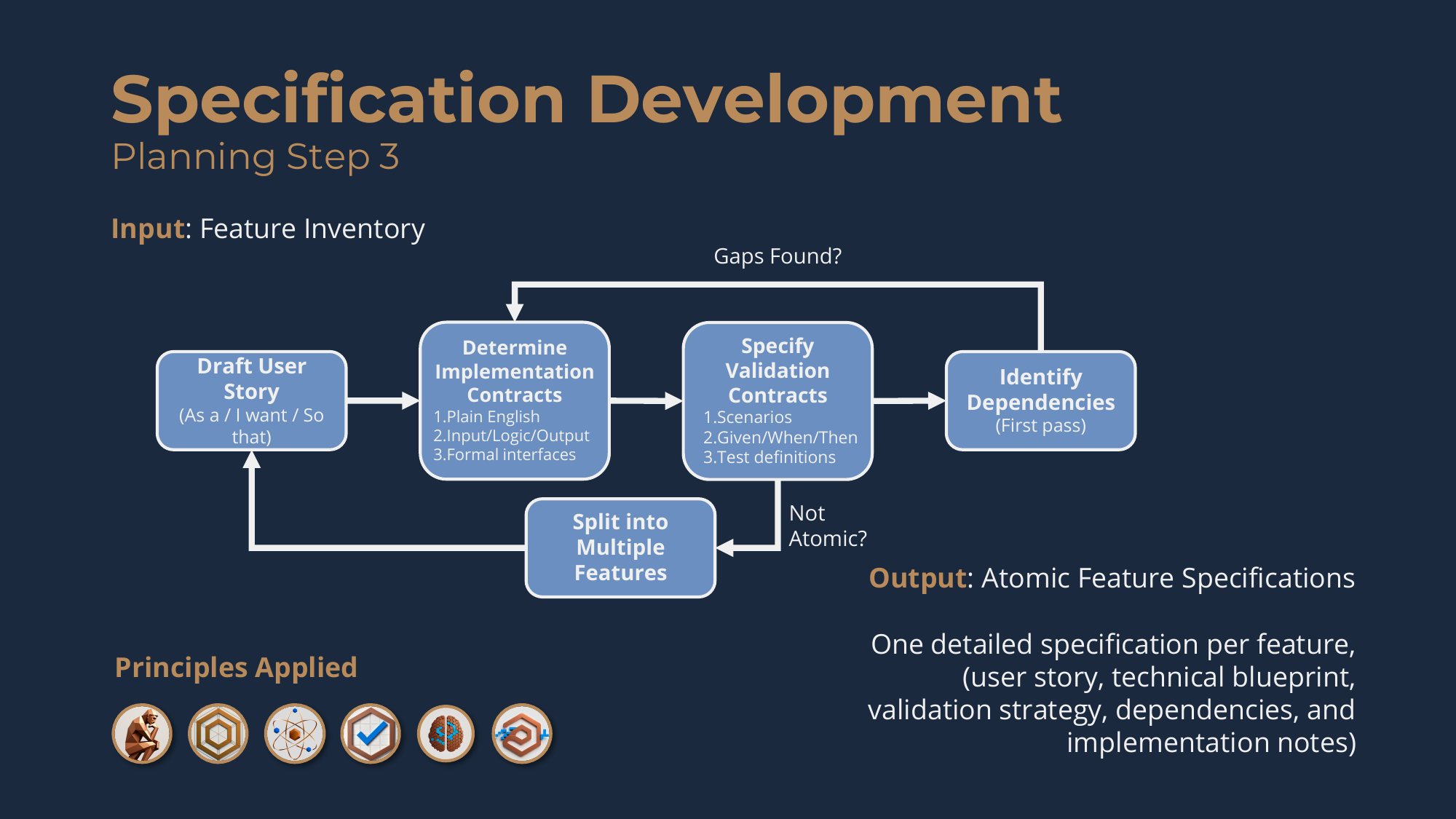
This is the critical step. The purpose is to transform each feature from the inventory into a complete, atomic, implementation-ready specification that defines exactly what to build, how it will be validated, and what it depends on.
You collaborate with an agent to refine each feature through a three-level pattern. First, a user story -- "as a [user type], I want to [action] so that I can [benefit]" -- capturing who needs this, what they're doing, and why. Then the implementation contracts, in three levels of increasing precision:
- Level 1, plain English -- what the feature does in natural language: what it receives, what it does, what it produces.
- Level 2, logic flow -- structured pseudocode with clear INPUT, step-by-step LOGIC, and defined OUTPUT.
- Level 3, formal interfaces -- exact signatures, data structures, and API specs: precise input types, return types, and errors.
Then the validation contracts, also in three levels:
- Level 1, plain-English scenarios -- every situation that needs validation: happy path, error cases, edge cases, security properties.
- Level 2, test logic -- each scenario as GIVEN/WHEN/THEN, with setup, trigger, and expected outcomes.
- Level 3, formal test definitions -- exact test interfaces with setup, inputs, precise assertions, and teardown.
Then you validate atomicity: can this be implemented in a single focused session? If the spec feels scattered or describes multiple capabilities, you split it and repeat. Finally you identify dependencies -- which other features must exist before this one can be implemented -- documented as explicit, binary dependencies: it either depends on another feature or it doesn't. The output is a complete Atomic Feature Specification for every feature in the inventory.
Planning Step 4: Dependency Analysis
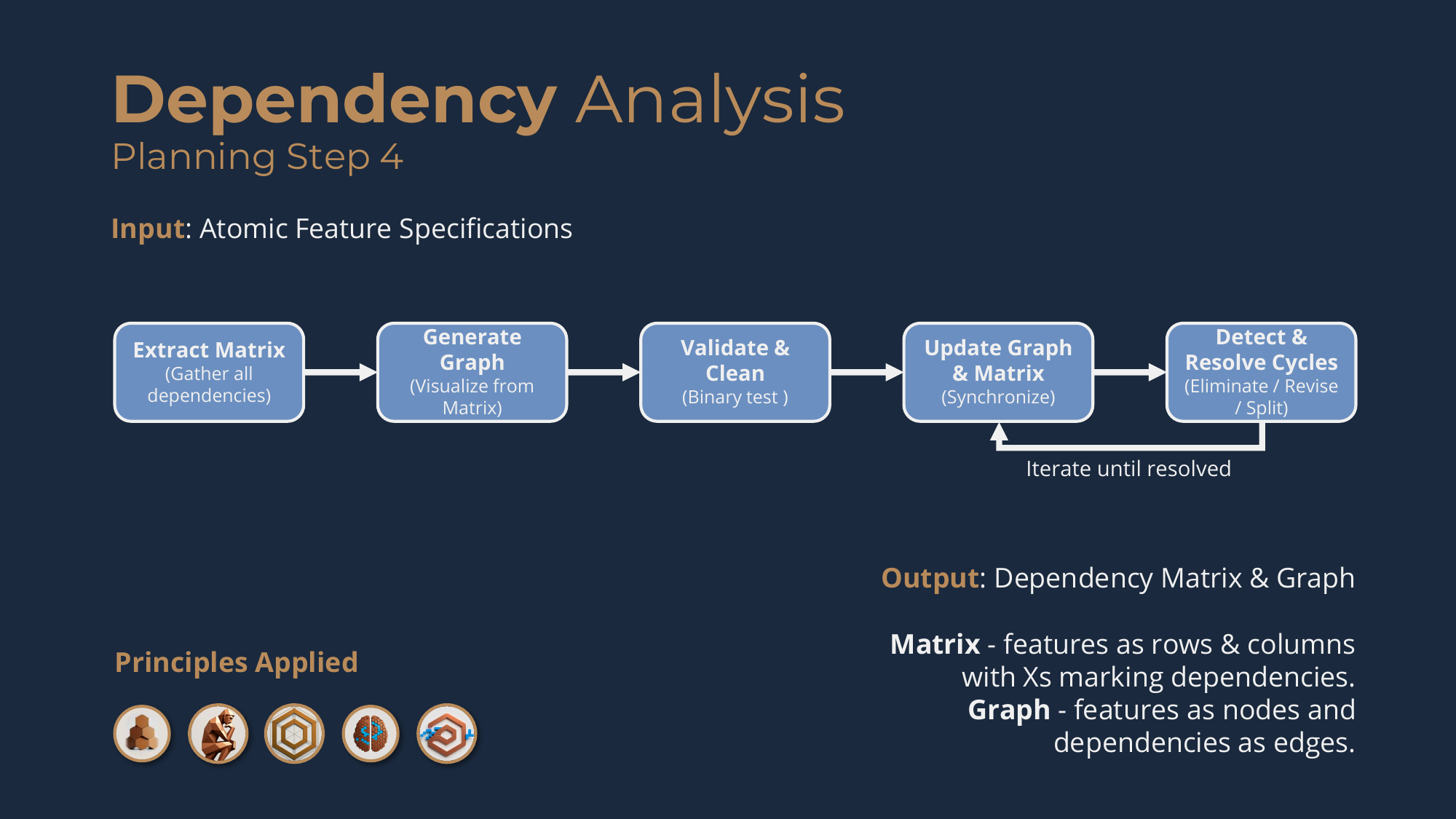
The purpose is to transform your complete set of feature specifications into a validated dependency matrix that defines the exact order features can be implemented in -- eliminating circular dependencies and revealing natural phases.
Your specs contain accurate dependency declarations, but they're scattered across individual documents. You have the local picture (feature X depends on feature Y) but not the global one. Without a synthesized view you can't see the complete graph, detect cycles that span multiple features, identify the natural implementation phases, or know what has to be built first.
So you extract the matrix -- every feature is a row and a column, and you mark an X where a row feature depends on a column feature. You generate a graph from it (Graphviz, Mermaid, your pick) with features as nodes and dependencies as edges, which makes cycles immediately visible as closed loops and reveals the layered structure. You validate and clean with the binary dependency test on every mark: does the row feature actually require the column feature's specific output, configuration, or functionality to work? If yes, keep it; if no -- if it's only coordination or tool-sharing -- remove it. You regenerate the graph, then detect cycles, and where you find them you apply resolution strategies in order: first dependency elimination (re-examine with the binary test), then revised specification (rethink interfaces so features don't need each other's output), then feature splitting (maybe it wasn't atomic), and only as a last resort, consolidation. You iterate -- update matrix, regenerate graph, recheck -- until zero cycles remain. The outputs are the validated Dependency Matrix and the Dependency Graph.
Planning Step 5: Implementation Plan Development
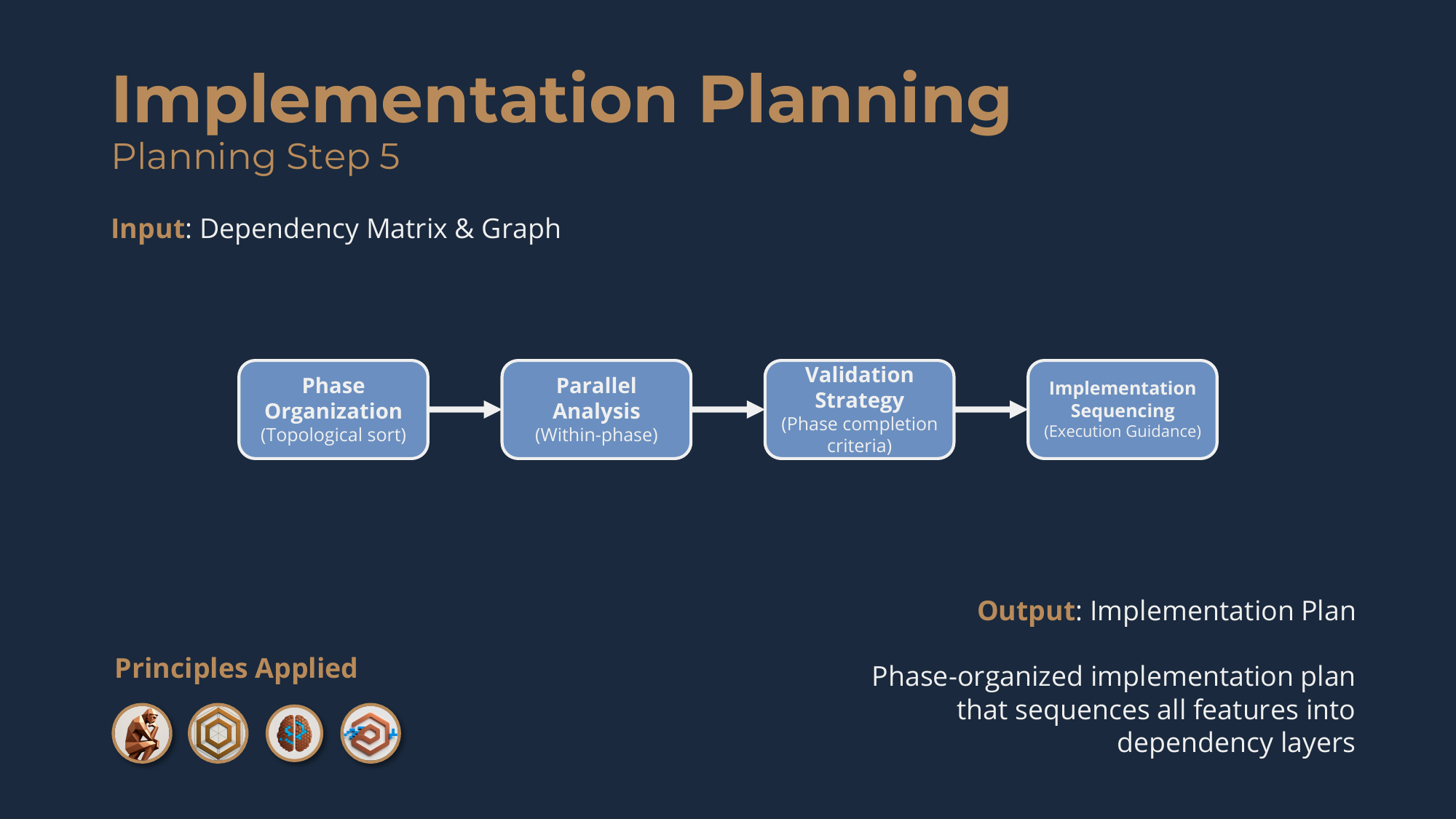
The final planning step transforms the validated dependency matrix into a comprehensive, phase-organized implementation roadmap -- sequencing features into dependency layers, defining phase completion criteria, and establishing the validation strategies that enable the implementation loop.
Without this, you face implementation chaos: even with complete specs and a validated matrix, you can't say which features come first and in what order, or when it's safe to start a feature that depends on earlier work. So you organize phases via a topological sort: features with no dependencies are phase one; features depending only on phase one are phase two; and so on, each phase depending only on previous phases. You verify that no two features within a phase depend on each other, and you identify the critical path -- the longest dependency chain. Then you do validation strategy planning: for each phase, binary success criteria -- what tests must pass, what integration points must work, how you'll verify features work together -- and feedback loops that enable autonomous refinement and binary progress tracking (a feature is implemented or it isn't; there's no 20%-done). Finally, implementation sequencing: phase gates, guidance for how the agent selects the next feature, a blocker-management process, and progress-tracking mechanisms at the feature level, the phase level, and along the critical path. The output is the Implementation Plan.
The Implementation Loop
Implementation is where your planning artifacts guide the transformation of specifications into working, tested software. Unlike planning, which is linear and proceeds through five distinct steps, implementation is a tight, rapid loop run repeatedly for each atomic feature.
The Multi-Sensory Feedback Loop

This is a really key idea. The agent implements code, then executes it while gathering feedback through three digital senses:
- a visual sense (what renders),
- an auditory sense (what the system reports), and
- a tactile sense (how interactions respond).
This sensory feedback provides rich diagnostic information about what's actually happening in the application. The agent also runs formal tests against the acceptance criteria -- but by correlating sensory feedback with test results, it understands both what failed, from the tests, and why it failed, from the senses. The loop continues until all acceptance criteria pass and all senses report clean execution.
Implementation Step 1: Context Assembly
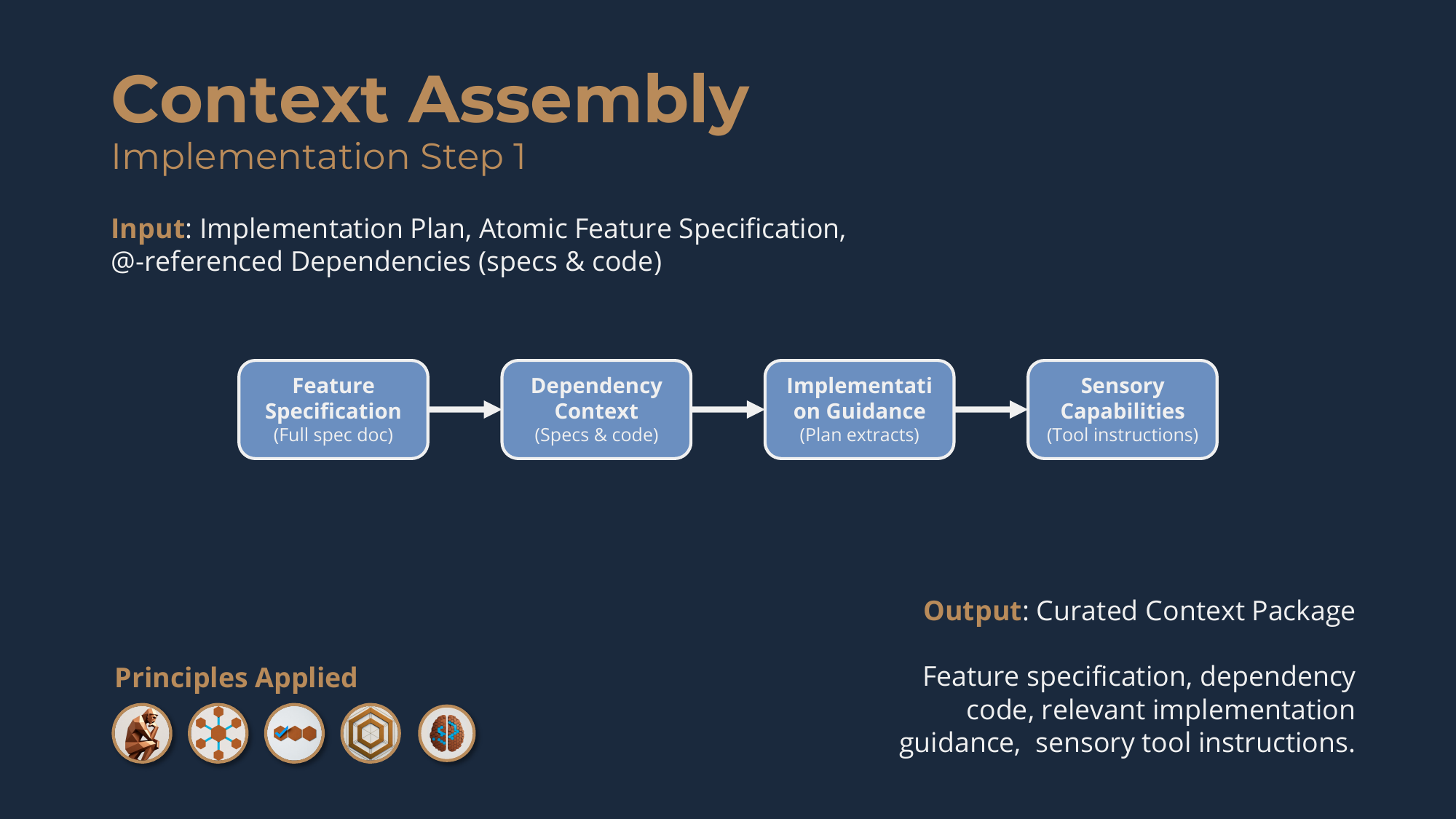
The purpose is to transform planning artifacts into a curated context package that enables autonomous feature implementation within a single coding session.
You have atomic features fully specified and sequenced, but you can't just throw everything at the agent and hope. Dumping entire planning documents into a session wastes context window on irrelevant information, leads the agent to make decisions without critical context (or to stop and ask), and turns what should be autonomous implementation into constant back-and-forth.
So you curate exactly what this one feature needs, in four steps. Feature specification assembly: include the complete spec -- user story, technical contracts, acceptance criteria -- and @-reference its dependencies; this is the primary blueprint. Dependency context gathering: follow those @ references, each pointing to a dependency's specification and its actual implemented code (per The Framework, all dependencies are implemented previously), so the agent knows exactly what to integrate with. Implementation guidance extraction: pull only the relevant sections of the Implementation Plan -- what phase this is, the phase completion criteria, the validation strategy. Sensory capability enablement: read the acceptance criteria to identify which senses are required -- visual language like "sees / displays / renders" needs the visual tools, logging and error language needs the auditory tools, interaction language like "clicks / submits / completes" needs the tactile tools -- and @-reference the appropriate tool-usage guides (written once per tool, reusable across all features). The output is the Curated Context Package.
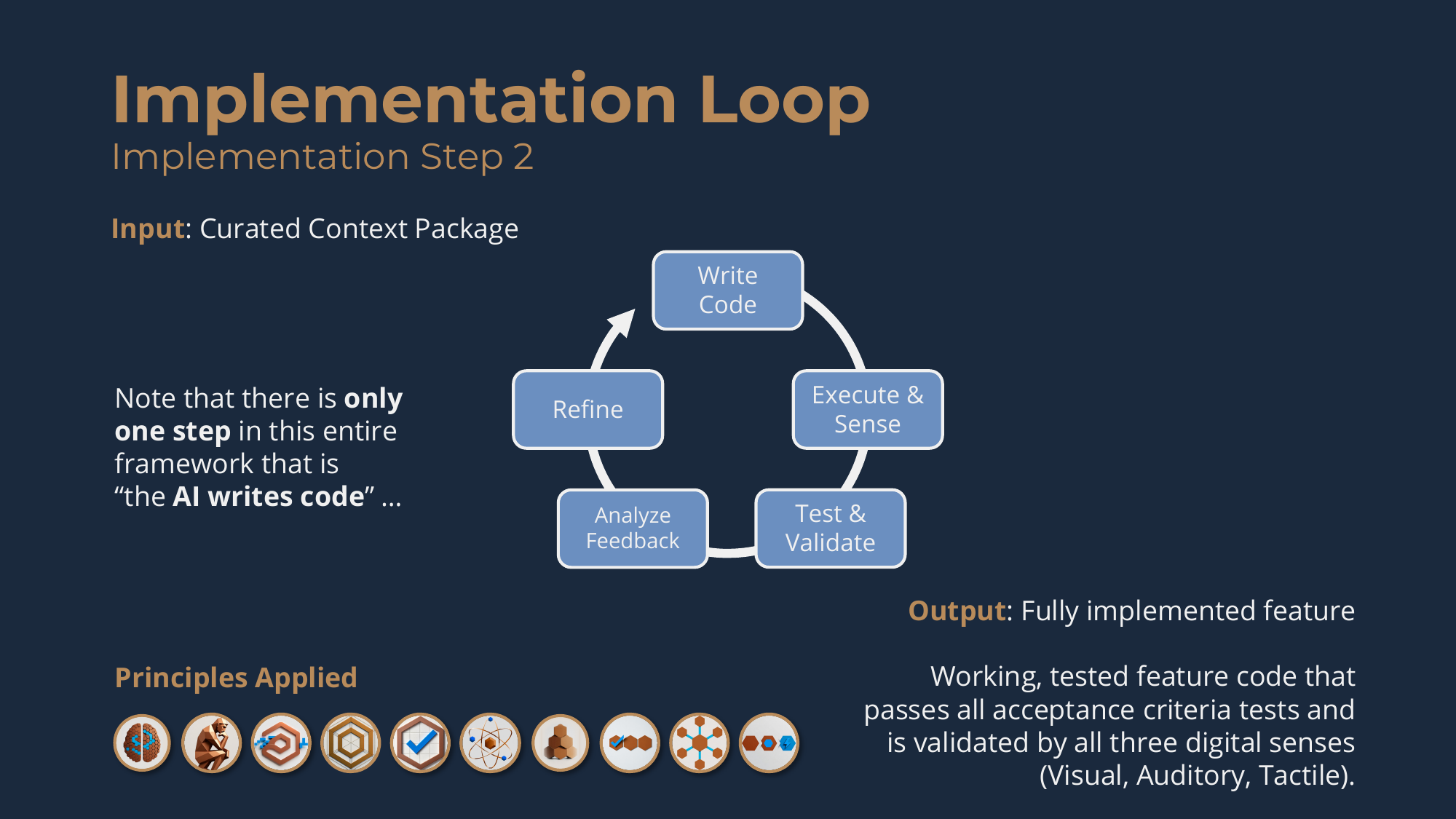
Implementation Step 2: The Implementation Loop
This is the only step in the entire Framework where the AI writes code. The purpose is to transform an atomic feature specification into working, tested code.
Without structure here, agents either write all the code before testing anything -- so problems accumulate undetected and you debug many interconnected issues at once -- or they write and test ad hoc, missing the problems tests don't catch: tests pass but the UI doesn't render, the workflow completes but errors fill the logs, the feature "works" but the interactions are broken. Because features are atomic, the complete implementation fits in one context window, so the agent keeps full understanding from start to finish -- no context loss, no reconstruction, no degraded fidelity.
The loop runs like this.
- Write code following the specification's technical contracts, translating all three levels into working code so interfaces, inputs, outputs, and error handling match the spec exactly.
- Execute and sense: run it immediately and gather comprehensive feedback through the three senses based on the acceptance criteria.
- Test and validate: run all the test scenarios from the validation contracts for binary pass/fail signals.
- Analyze feedback: correlate signals across all active senses and the test results -- multiple senses reporting the same issue confirm a diagnosis, conflicting signals reveal hidden complexity -- and this integrated view shows both what failed and why, enabling
- Targeted refinement.
You loop until the feature is complete: all tests pass and all senses report clean execution -- no errors in logs, no rendering issues, interactions working. Then the agent makes an atomic git commit containing only this feature's changes, with a structured message including the feature ID, a specification summary, validation confirmation, and implementation notes. The output is a fully working, tested feature, validated by all three senses and ready for integration.

We've even blown the tiger's mind, now! Let's round the corner into tools.
The Tools
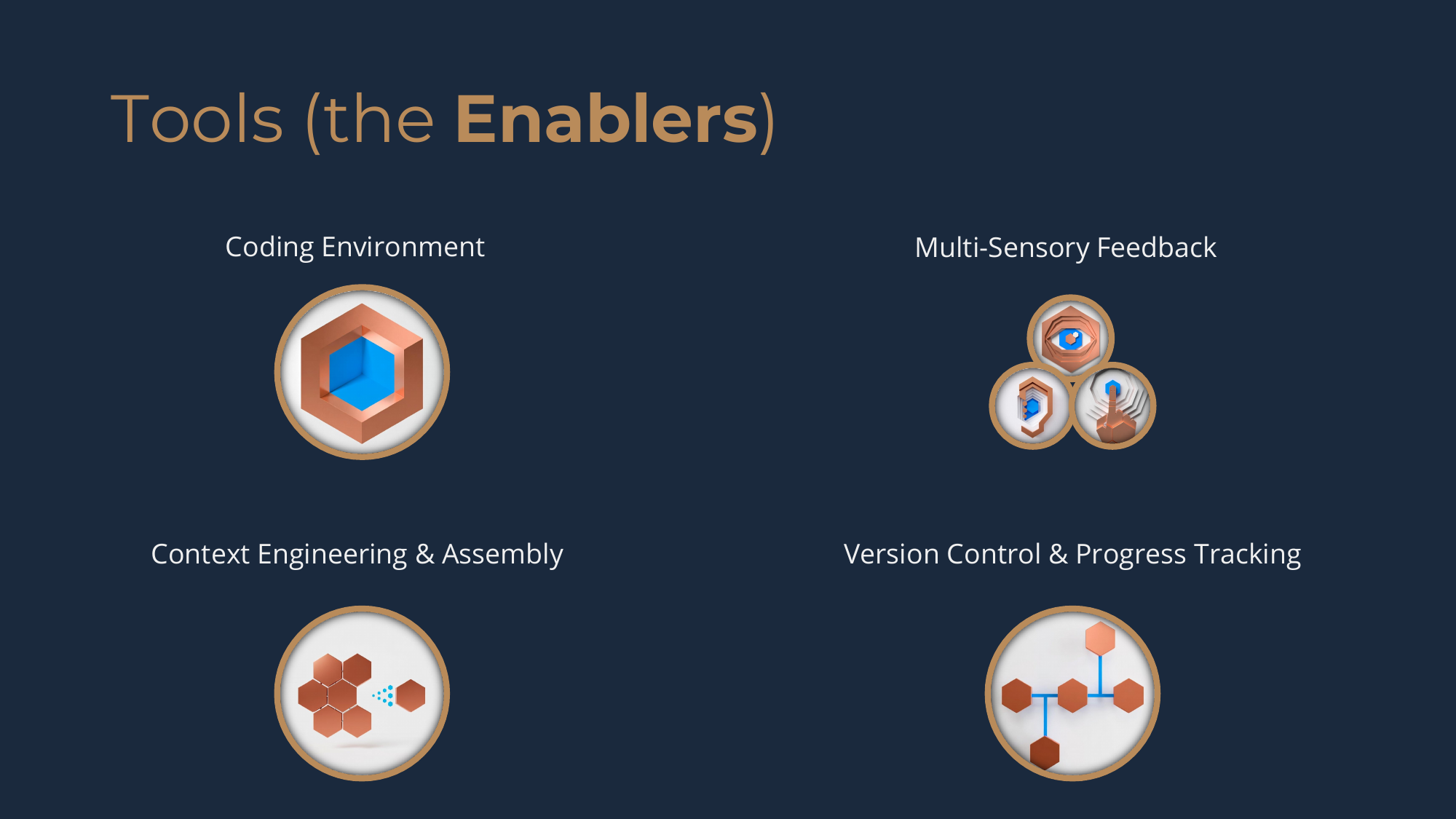
The Framework requires four foundational capabilities that enable the work done through the process. The Framework isn't prescriptive about which tools -- only about the capabilities those tools should possess.
Coding Environment

A complete development workspace that supports two fundamentally different kinds of work happening at once: your architectural thinking and planning, and the agent's autonomous implementation and testing. Four core components:
- An AI coding agent -- obviously.
- An execution sandbox -- a safe, isolated environment where all agent-written code executes and tests run. Autonomous implementation needs the freedom to experiment, iterate, and occasionally break things; the sandbox gives complete development capability in a disposable, risk-free space with easy reset and no consequences for failure.
- An IDE (or a text editor, if you must) -- pick the one that suits you; I'll avoid the holy wars.
- Voice input -- a rapid-capture system that converts speech to text at thinking speed. Planning means externalizing architectural thinking, which is often incomplete, exploratory, and iterative; voice removes the typing bottleneck and lets you think out loud far faster than you can type. I can't oversell how massively impactful a good voice-input tool is in applying The Framework.
Multi-Sensory Feedback System

A comprehensive validation infrastructure that gives agents the ability to observe their implementations through three complementary digital senses, enabling autonomous refinement through the same breadth of observation humans use during development:
- Visual sense tools -- direct observation of what was produced: UI rendering (screenshots, layout, styling), system state (database contents, configuration, session data), and code structure. Visual observation catches what logs and tests miss -- broken rendering, incorrect state, structural issues.
- Auditory sense tools -- what the system reports: logs (the system narrating its operations), errors and warnings, API responses, and stack traces. This explains why things fail, not just that they failed.
- Tactile sense tools -- active interaction testing: simulating and executing user workflows end-to-end, API request/response cycles, performance validation, security checks, and integration testing. These reveal whether the software behaves correctly under actual use, not just in isolated tests.
- An orchestration layer (MCP or equivalent) -- the protocol layer that surfaces these tools and coordinates them into one integrated feedback system, delivering structured sensory data so the agent understands both what failed and why.
Context Engineering and Assembly

A systematic approach to assembling focused, complete context packages for agents:
- An
@cross-reference system -- declarative linking that lets documents explicitly reference other documents, code files, or sections, enabling automatic context assembly by following the dependency chains. These aren't hyperlinks for human navigation; they're actionable declarations that automation can follow. - Slash commands (or your environment's equivalent) -- process automation that triggers multi-step framework workflows from a single invocation, especially for context assembly, template instantiation, and implementation-session initialization.
- A template system -- structured templates for every framework artifact (Master Project Specification, Feature Specification, Dependency Matrix, Implementation Plan, Implementation Record) that ensure consistent format and completeness. Without templates you reinvent the structure every time, and starting from scratch is exhausting.
- Markdown documentation format -- agents are so literate in it that it's vital to have tooling that converts inputs to markdown rapidly. Anything you want to communicate to an agent should be instantly convertible to markdown in your toolchain.
Version Control and Progress Tracking

A dual-mechanism system for provenance and current-state visibility:
- A version control system -- I'll just say it: Git, or the equivalent. Implementation history through atomic feature commits. It's like saving progress in a video game: obvious and essential.
- The Implementation Plan with progress tracking -- the same planning artifact from step five, doing double duty. Git shows what changed and when, but not the project's state; the Implementation Plan fills that gap, tracking which features are complete, which are blocked, and what's next. This is the simplest form of project tracking -- it can get more complex and more integrated -- but it's enough.

For the curious, that's my own tool stack.
The Morning After
That's The Framework: the principles, the process, and the tools -- and the way they reinforce one another, with each process step and each tool capability tracing back to the principles. Build this way and the Monday after isn't a hangover. You understand the software, you own it, you can maintain and extend it -- and you're a better engineer than you were the feature before.

The software is valuable. The engineer you become is exponentially more valuable.

If you enjoyed this and want the slides, the soundtrack, and the other resources, I built a site just for the talk: vibecodinghangover.com. Happy hacking.