
Build the Gym, Not the Dataset
Stefano Fiorucci (X, LinkedIn, GitHub) is an AI/Software Engineer at deepset, where he contributes to the open-source LLM framework Haystack. At AI Engineer Europe 2026, he made a case that the next leap for open-source language models isn't better datasets -- it's better environments. The kind where models can act, fail, and learn from the outcome.
"This is exciting because the model is no longer limited by the quality of human examples. Through trial and error it can discover more efficient reasoning strategies."
From Imitation to Interaction
Fiorucci frames the shift by contrasting two training paradigms. Supervised fine-tuning is statistical imitation -- you show the model curated examples and it learns to mimic them. Reinforcement learning with verifiable rewards (RLVR), the approach used in DeepSeek R1, is different. The model generates reasoning traces, its answers get checked against ground truth, and rewards drive the next update. No curated dataset required -- just a clear reward signal and room to explore.
He paraphrases Andrej Karpathy: giving an LLM the opportunity to interact, take actions, and see outcomes means "you can hope to do a lot better than statistical expert imitation."
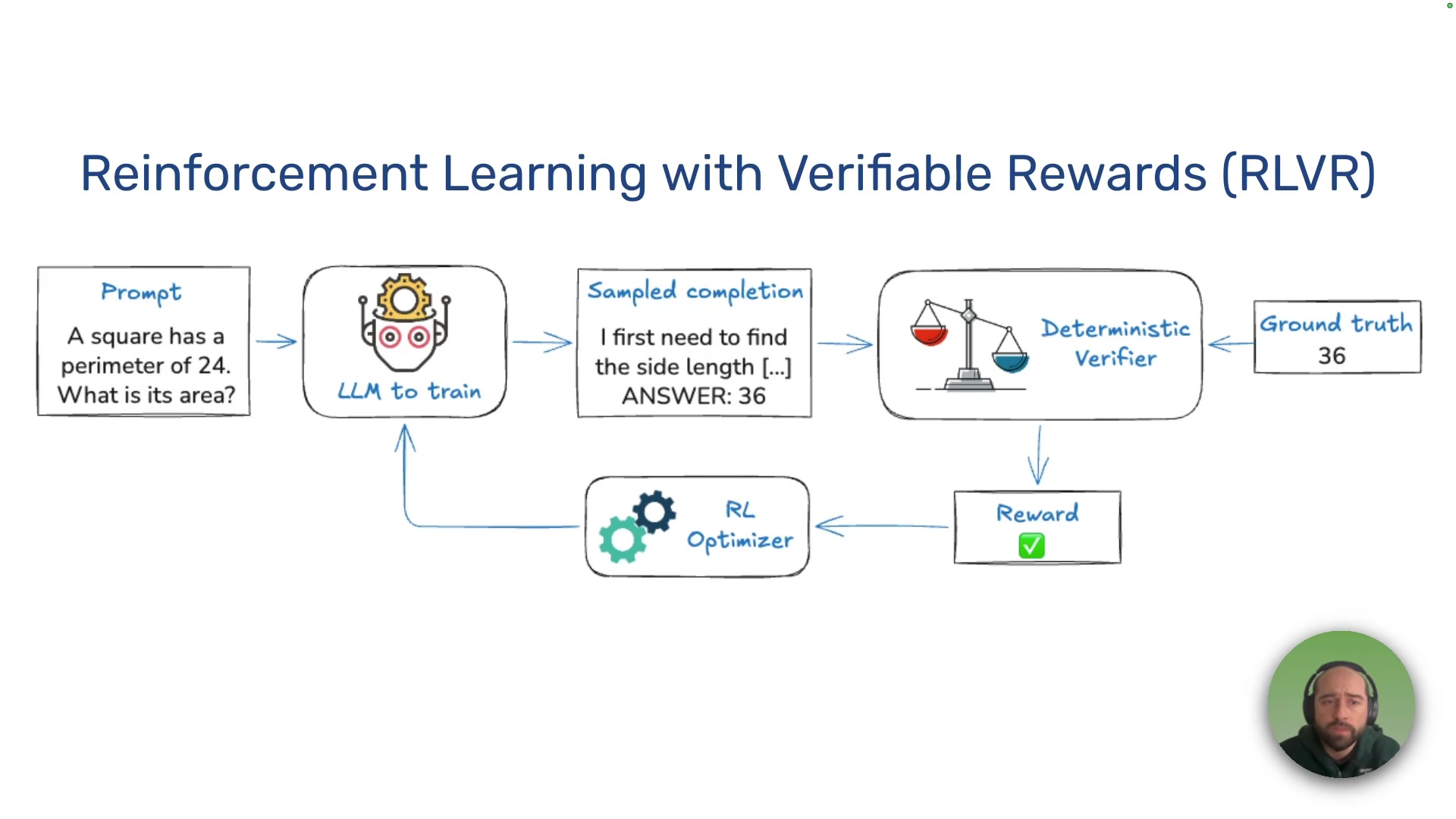
The mapping is straightforward. The language model is the agent. The environment encompasses the task, data, analysis, and scoring rules. The reward is the verification signal. What's less straightforward, Fiorucci argues, is the software engineering problem of making these environments reusable.
Environments as Software Artifacts
"Too often environments are locked into specific training stacks, making them difficult to reuse. And as a market for closed-source environments emerges, these open initiatives ensure we have a robust alternative."
This is where Stefano's core reframing comes in. RL environments for LLMs should be installable, distributable Python packages -- not one-off training scripts welded to a specific framework. He walks through an open-source library called Verifiers that implements this idea with a hierarchy of environment types:
- Single-turn -- one model interaction (e.g., reverse a text string)
- Multi-turn -- multiple exchanges with state tracking and stopping conditions
- Tool environments -- models call Python functions during rollouts
- MCP environments -- auto-connect to Model Context Protocol servers
- Stateful tool environments -- per-rollout persisted state like database connections
The library abstracts model serving behind OpenAI-compatible API endpoints and integrates with multiple training frameworks. There's also a community hub for sharing environments -- the point being that if environments can be packaged and shared, the open-source ecosystem doesn't fall behind closed models just because it lacks training infrastructure.
"We don't want open-source models to lag behind just because they lack the right playground training."
Teaching a Small Model to Play Tic-Tac-Toe
The demo is where theory meets practice. Fiorucci takes LFM2, a small open model by Liquid AI, and tries to make it a competent tic-tac-toe player through a multi-stage pipeline.
The baseline is bleak. GPT-5 mini plays well and follows the expected format. LFM2 struggles with format, makes invalid moves, and loses constantly.
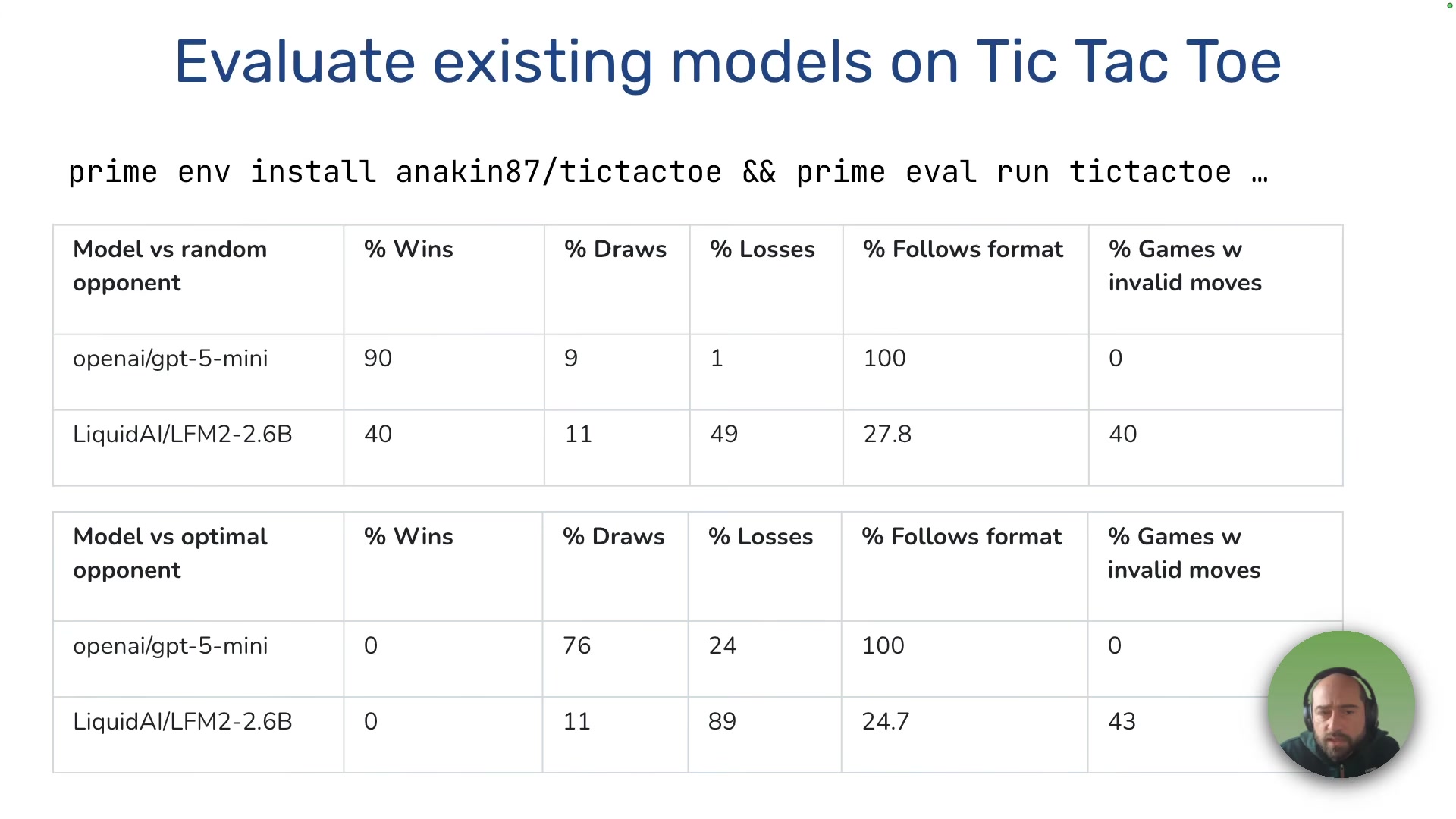
Stage 1: SFT warm-up. Generate 200 synthetic games from GPT-5 mini, filter out losses, fine-tune LFM2. This teaches format and valid move syntax -- nothing more. Training takes minutes on a single 96GB GPU.
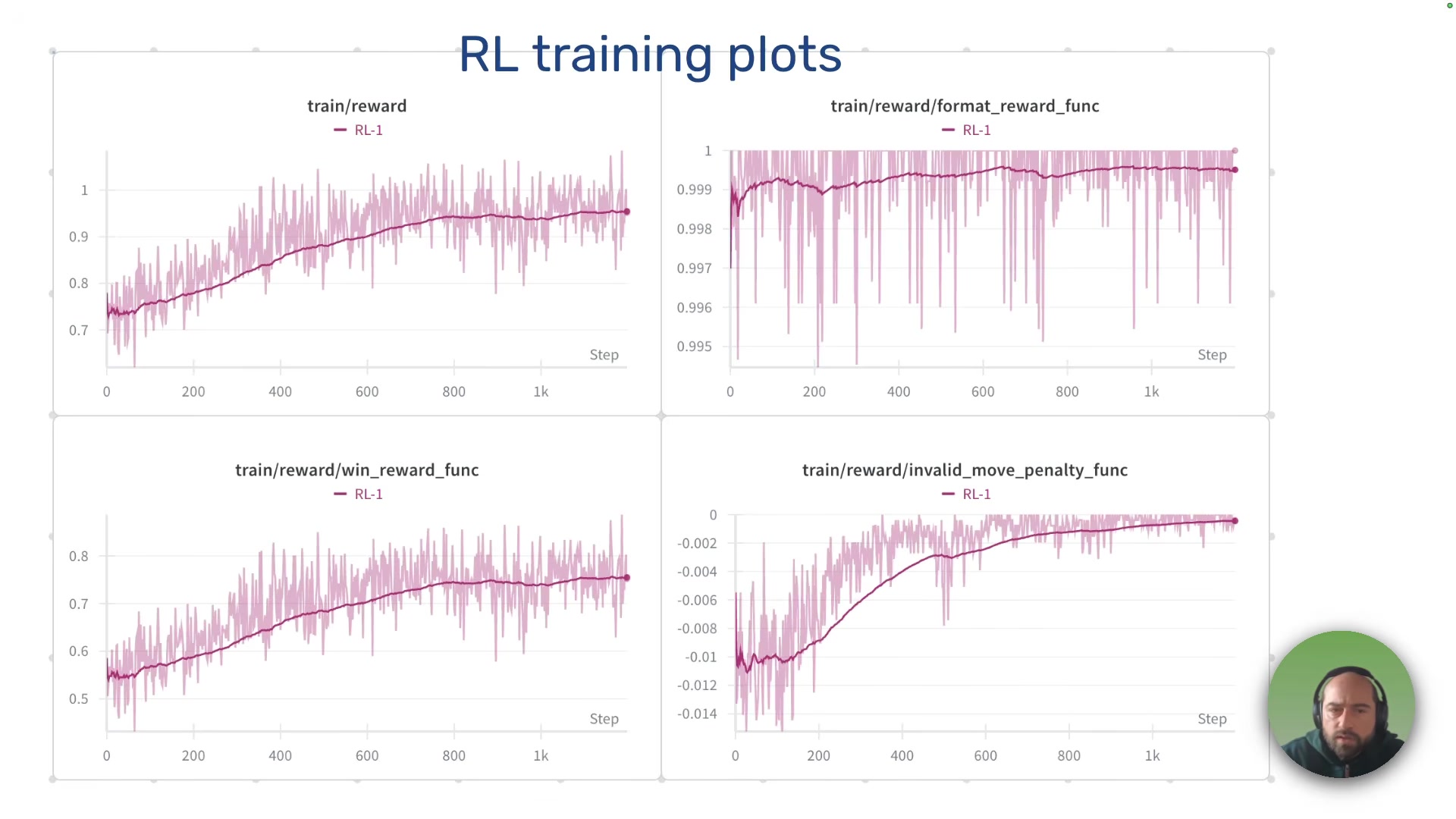
Stage 2: RL training (round 1). Using CISPO (an improvement on DeepSeek's GRPO algorithm), the model plays against opponents with configurable skill levels -- random move probability ranging from 20% to 70%. Several design choices matter here:
- Stratified sampling ensures each training batch contains a balanced mix of opponent difficulties
- Deterministic seeding per example and per turn, so reward differences reflect model skill rather than opponent randomness
- Invalid move tolerance with a small penalty (-0.1) rather than immediate game-over, preserving learning signal for small models
- Minimum batch size of 256 -- smaller values caused training instability and collapse
Stage 3: RL training (round 2). Tougher opponents (0-25% random moves), higher temperature to encourage exploration. An initial performance dip -- interpreted as an exploration phase -- followed by recovery and improvement.
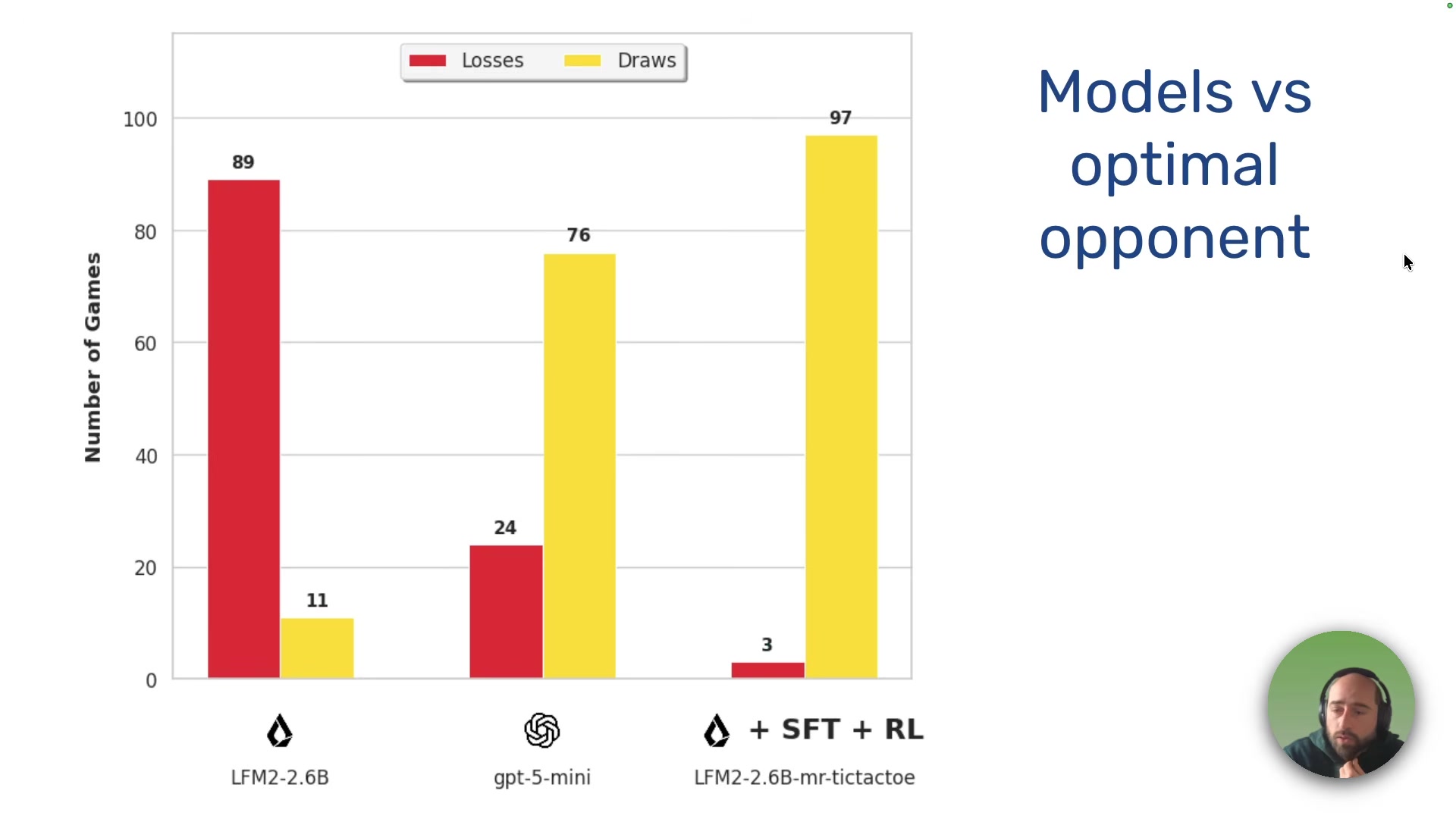
The Student Surpasses the Teacher
The result: after round 1, the small model dominates random opponents and draws roughly 85% of the time against optimal play. After round 2, it outperforms GPT-5 mini against an optimal opponent.
This is the non-obvious punchline. Fiorucci used GPT-5 mini to generate the initial training data, then used RL to push a small model past the model that taught it. His argument: if you can define a clear reward signal, the ceiling for a small specialized model isn't set by its teacher.
Lessons from Failed Experiments
Fiorucci is candid about what went wrong along the way:
- Batch size too small leads to instability and model collapse -- the model learns from too few games and opponent types at once.
- Hidden environment biases can sabotage training. His Minimax opponent implementation always selected the first valid position when moves had equal scores, so the model memorized one opponent's behavior instead of learning general play.
- Starting from a reasoning model with long thinking traces on limited GPU meant forced truncation, which wastes compute budget and risks damaging the model's capabilities. Better to start from an instruct model.
- Very small models may simply lack capacity for a given task. Evaluate base models first and look for promising behaviors before committing to training.
"Reinforcement learning is slow and takes time to see progress. If you continually monitor it, you risk the temptation to stop it and tweak something prematurely... So start training and go for a walk."
The Takeaway
Fiorucci's argument is practical: the barrier to training capable small models isn't algorithmic sophistication -- it's the lack of reusable, shareable environments where models can learn through interaction. Build the environment, define the reward signal, and a small model can beat a large one on a specific task at a fraction of the cost.
"You can do this at home too. If you can define a clear reward signal, you can build an environment and train a small specialized model to beat a large closed model on a specific task at a fraction of the cost."
Stefano Fiorucci spoke at AI Engineer Europe 2026. AI/Software Engineer at deepset.
Watch the full talk | LLM RL Environments Lil Course | Slides | LinkedIn | X