
Hey data hackers! Looking for a rapid way to pull down unstructured data from the Web? Here’s a 5-minute analytics workout across two simple approaches to how to scrape the same set of real-world web data using either Excel or Python. All of this is done with 13 lines of Python code or one filter and 5 formulas in Excel.
All of the code and data for this post are available at GitHub here. Never scraped web data in Python before? No worries! The Jupyter notebook is written in an interactive, learning-by-doing style that anyone without knowledge of web scraping in Python through the process of understanding web data and writing the related code step by step. Stay tuned for a streaming video walkthrough of both approaches.
Huh? Why scrape web data?
If you’ve not found the need to scrape web data yet, it won’t be long … Much of the data you interact with daily on the web is not structured in a way that you could easily pull it down for analysis. Reading your morning feed of news and catch a great data table in the article? Unless the journalist links to machine-readable data, you’ll have to scrape it straight from the article itself! Looking to find the best deal across multiple shopping websites? Best believe that they’re not offering easy ways to download those data and compare! In this small instance, we’ll explore augmenting one’s Kindle library with Audible audiobooks.
Audiobooks whilst traveling …
When in transit during travel (ahh, travel … I remember that …) I listen to podcasts and audiobooks. I was, the other day, wondering what the total cost would be to add Audible audiobook versions of every Kindle book that I own, where they are available. The clever people at Amazon have anticipated just such a query, and offer the Audible Matchmaker tool, which scans your Kindle library and offers Audible versions of Kindle books you own.
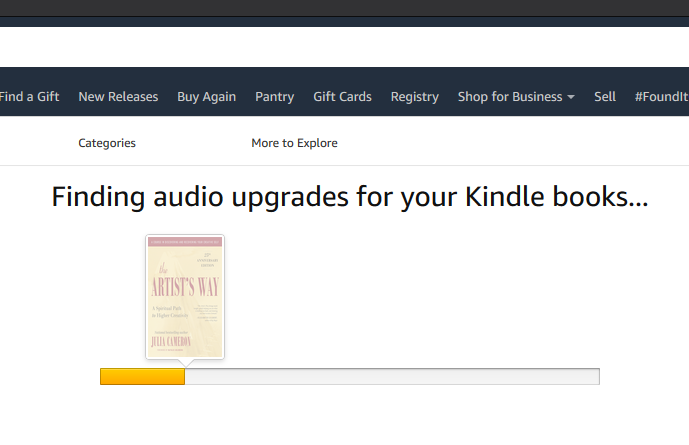
Sadly, there is not an option to “buy all” or even the convenience function of a “total cost” calculation anywhere. “No worries,” I thought, “I’ll just knock this into a quick Excel spready and add it up myself.”
Part I: Web Scraping in Excel
Excel has become super friendly to non-spreadsheet data in the past years. To wit, I copied the entire page (after clicking through all of the “more” paging button until all available titles were shown on one page) and simply pasted this into a tab in the spready.
Removing all of the images left us with a column of a mishmash of text, only some of which is useful to our objective of calculating the total purchase price for all unowned Audible books. Filtering on the repeating “Audible Upgrade Price” text reduces the column down to the values we are after.
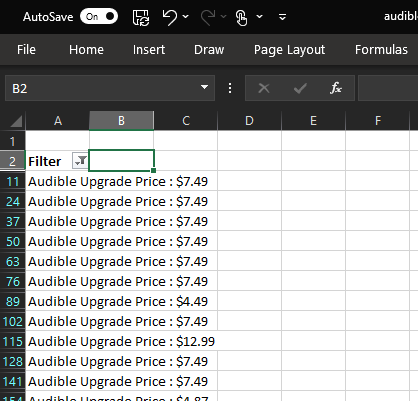
Perfect! All that remains is a bit of text processing to extract the prices as numbers we can sum. All of these steps are detailed in the accompanying spreadsheet and data package to this post.
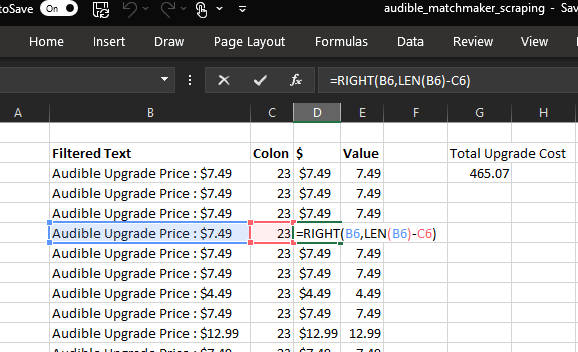
$465.07 … not a horrible price for 60 audiobooks … just about $8 each. (As an Audible subscriber, each month’s book credit costs $15, so this is roughly half of that cost and not a bad deal …) NB – we could have used Excel’s cool Web Query capabilities to import the data from the website, though we’ll cover that separately as we cover scraping Web data requiring logins elsewhere.
I’m sure my Kindle library is like yours, in that it significantly expands with each passing week, so it occurred to me that this won’t be the last time I have this question. Let’s make this repeatable by coding a solution in Python.
Part II: Web Scraping in Python
The approach in Python is quite similar, conceptually, to the Excel-based approach.
- Pull the data from the Audible Matchmaker page
- Parse it into something mathematically useful & sum audiobook costs
Copy the data from the Audible Matchmaker page
The BeautifulSoup library in Python provides an easy interface to scraping Web data. (It’s actually quite a bit more useful than that, but let’s discuss that another time.) We simply load the BeautifulSoup class from the bs4 module, and use it to parse a request object made by calling the get() method of the requests module.
Parse the data into something mathematically useful
Similar to our approach in Excel, we’ll use the BeautifulSoup module to filter the page elements down to the price values we’re after. We do this in 3 steps:
- Find all of the span elements which contain the price of each Audible book
- Convert the data in the span elements to numbers
- Sum them up!
Donezo! See the accompanying Jupyter Notebook for a detailed walkthrough of this code.
There it is – scraping web data in 5 minutes using both Excel and Python! Stay tuned for a streamed video walkthrough of both approaches.